Geographic databases of political boundaries, streets and water features are quite old, dating back nearly to the beginnings of GIS. Digital neighborhood boundaries are relative newcomers, dating back only a few years. With January's announcement from Zillow that the company would share its neighborhood boundary data for free, this seems a good time to explore the nature of this data layer and how some of the major players approach its creation.
Maponics
Darrin Clement, CEO of Maponics, explains that the company put a "toe" into neighborhood data when its direct mail data users began asking the company to parse geography not by city boundaries but something smaller. Maponics offered ZIP Code data, allowing direct mailers to select which ZIP Codes were of interest. But the mailers wanted more precise data – they wanted to only mail to the "wealthy" or perhaps "less wealthy" parts of a ZIP Code. Because those who work in direct mail know their regions well, it was possible for Maponics to provide postal carrier routes (mail carriers' "boundaries") and have the clients "draw" the areas of interest to determine addresses of interest.
That, reports Clement, would have been a fine solution, until local search came along. The players in local search didn't have the local intelligence of the direct mail players, but they still wanted to target by neighborhood. Thus, Maponics found a market for a new type of data, one the company did not yet offer. So they built it.
Building Squishy Data
Neighborhoods are not usually delineated by the government, but rather by those who live in the area. The exact edges are often fluid. The names are also fluid. Clement is the first to admit neighborhood boundaries are "squishy." How then does the company determine where the digital lines are drawn?
At Maponics, there are two parts to data creation. The first focuses on finding resources. What public and private data exist about neighborhoods? Maponics staffers seek and gather information that's available. What if such data do not exist for a city? Then the company creates the boundaries with input from its many customers, especially those in real estate, who, like the direct mailers, know their geographies. Clement chooses the term "expert sourcing" to describe a process that includes only those with knowledge of the topic, to contrast it with "crowd sourcing," where just about anyone can have input.
The second part of the process involves pulling together the resources. That includes everything from, at times, digitizing from paper maps, to reprojecting data files, to converting formats, to scrubbing "dirty" data, and performing extensive quality control. Clement notes that some think of quality control as "checking the spelling of neighborhood names," but he is quick to point out that it is far more complex and time-consuming than that. Maponics is methodical about its data processing. The company offers neighborhood data for more than 350 cities across the U.S. and Canada; more than 100 cities worth of data are waiting in the wings for future releases.
 |
How does Maponics deal with the fluidity of data, that is, boundaries that may shift depending on the source? Initially, the company decided that rather than putting its own interpretation into the fuzziness of the data, it would draw firm lines. Other competing solutions effectively "hard-code" the fuzziness by making neighborhoods as big as they could possibly be and creating overlaps, meaning that a single address could be in one or more neighborhoods. Clement puts it this way, "We do our best to draw a 'consensus perception' boundary. If the users want to include a measure of fuzziness, they can easily create their own buffers to indicate it and tune the fuzziness to their application. We feel it's best to draw the lines and then advise clients on how to include uncertainty using their GIS tools." He notes that if Maponics allowed anything wider than a line, it could get "sloppy" in its boundary drawing. The company offers quarterly updates on its neighborhood boundaries that include both new areas of coverage and updates to existing boundaries.
The other fuzziness in neighborhood data comes in naming. As an example, he notes that more and more communities are renaming themselves, sometimes because their original name is no longer politically correct. Says Clement, "Tables of alternate names are important to our customers, along with the hierarchy of macro-neighborhoods and sub-neighborhoods." The company will often capture such changes from a unique source: "social blogs." Clement says that some 20% of the neighborhoods the company covers host blogs that offer insight into such changes.
Urban Mapping
Ian White, founder of Urban Mapping Inc. (UMI), recalls his first experience with neighborhoods in a Zagat guide in the 1980s. He notes that arranging the printed city-based books by neighborhood made searching easier. But he is quick to note that local search has really pushed the development of electronic datasets for neighborhoods. With an interest in spatial cognition and urban environments, White never felt that early local search "worked." Using a tool to find a coffee shop by city, state or even ZIP Code, he points out, simply made no sense.
So, he moved his hand-drawn neighborhood maps to another medium and launched UMI. He learned quickly that existing data models and geographic tools didn't have exactly what he needed to create the boundaries the way he envisioned them. He didn't like maps where neighborhood names were left off, and he was only slightly happier when they were represented by just a point marker. He wanted the map created with neighborhood data to be something "you could act on." He is aware that the boundary he draws might be considered "wrong" by some, but at least it provides information that could enhance the next action – like walking to a movie or coffee shop.
Inclusive Neighborhoods
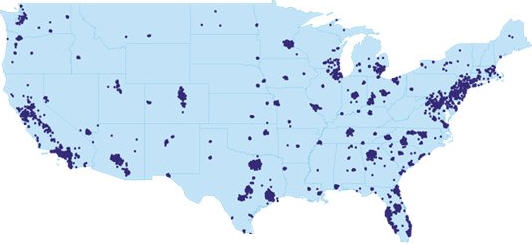
Thus UMI's datasets are built on a very inclusive representation of the data. The company's philosophy is that "exclusivity is wrong," when it comes to neighborhoods. That means that if data suggest that a street is in two different neighborhoods, it should be represented that way in the data. While neat lines on a map may be how a particular software model addresses area features like neighborhoods, "it's not," says White, "how people understand them." In UMI's representation of New York neighborhoods a coffee shop or bar may be in both Noho and Soho.
How, then, are the data used to provide information on which to act? If a location is in two neighborhoods, how do you answer the question, "Which neighborhood is it in?" UMI offers rules of "dominance" when this occurs to choose the "best" answer, depending on the situation. Dominance is based on a variety of factors concerning the two (or more) neighborhoods. The company's data also provide a hierarchy, such that a location is assigned to one or more neighborhoods, but also to the level of geography above, so the bar in Soho also knows it's in "downtown." Again, one or both of these geographic labels may be valuable depending on the application. Finally, UMI's data include a wide variety of aliases, synonyms and exonyms for neighborhoods. Aliases are simply different names for (at times) the same area. For example, in New York, Hell's Kitchen is also known as Clinton. Some of the different name choices are historic; others exist in the same period. Synonyms are different ways of referring to the same name: SoHo and South of Houston refer to the same neighborhood in San Francisco. Exonyms are names used by those outside the area to describe it. Prague is the name outsiders call a place that is locally called Praha. Beijing was once Peking to the outside world. Often, White suggests, different groups within cities may use an ethnic or altered ethnic name for the area.
 |
Creating Data
How does UMI put together its data? The company has relationships with municipalities and works with the real estate community, hospitality industry, local media and retail chains to collect data and track changes. It also draws on experts, including some 40-60 contract researchers with specific cultural familiarity with the area of interest. The company has a rigorous quality assurance/quality control (QA/QC) plan and offers quarterly updates, though typically updates come out more often than that. UMI offers U.S. coverage of more than 450 cities; Canadian and European coverage adds an additional 150 cities.
White is excited about adding not only more coverage to UMI's offerings, but also more details to its existing coverage. "People don't change," he notes, suggesting that the name a person associates with an area usually remains constant, even though others may alter or update that name over time. UMI wants to offer data that are reflections of the facts on the ground, with as much variety, nuance and variability as is found there.
Zillow
The big news in neighborhood data in January was Zillow's announcement that it would make its neighborhood boundary data available for free in shape file format under a creative commons license (attribution/share alike). The company's blog post that discusses data sources describes them as follows: "various tactics, including calling individual chambers of commerce, tourism and convention boards, speaking with real estate agents and community members in these areas, as well as using available online local sources." And, it tackles the big question: "Why?"
"Here at Zillow, we're all about transparency - we think a freely available and totally transparent nationwide data-set of neighborhoods will result in some great innovation that we're excited to check out. ...Additionally, it's a way for people to use and contribute to our growing database to help improve the boundary lines..."
Reaction was strong. Ed Parsons at Google called it the "story of the year so far." Others, like Marc at GeoNames, felt the licensing was too strict to make the data widely useable.
Zillow's Vision
Stan Humphries, Zillow's vice president of data and analytics, provides some insight into the history of the neighborhood boundary data. It's the same dataset that the company uses in its online applications. According to Humphries, the company began "playing around with neighborhoods starting before launch two years ago, however the project really got started around February of 2007."
A main reason to "give away" the data, says Humphries, is to create better data. "At Zillow, we not only get to give back to the developer community by offering up these boundaries for free, but we also do gain valuable information in return in the form of potentially more accurate boundaries to upload onto our site. To date, we've spent a lot of time, and therefore money, determining these initial boundaries, and are now looking forward to getting input from folks who likely know a given area much more intimately than we do."
Humphries offers a few more details on the data creation process: "We started this process, in most cases, by looking at an initial map of some type, either hardcopy of a digital image or, in some cases, written descriptions of the physical boundaries of neighborhoods. We then converted these into boundaries in our GIS software and used the tactics listed above to define these even further. We also utilized company employees, real estate agents and other professionals familiar with the given city who were willing to assist Zillow."
As for QA/QC, "there was a great deal of internal QA to clean up the data files themselves and some level of internal/external review of the actual boundaries themselves to make sure they were consistent with general conceptions of neighborhood boundaries." Still, he is quick to point out that "neighborhoods themselves are fluid over time and there's always going to be a healthy amount of debate about how to draw these lines."
Zillow's Data
Zillow's neighborhoods do not overlap, or as Humphries puts it: "Neighborhood boundaries are concrete." In the future, the company would like to support "neighborhood hierarchies in which neighborhoods may be nested within other neighborhoods." For now, there is only one name per neighborhood, but Zillow is looking to support alternative names in the future.
Update timing is not yet set. "We're working on plans right now on how best to incorporate user input on small changes in the boundary definitions. Our current plan is to wait until we have some critical mass of small changes (or several new boundary files for new cities) before creating a new set of all boundaries for distribution."
Humphries points to quite a lot of interest in the files to date and notes that Redfin, a real estate broker, is already a user. He expects more in the coming months.
Positioning
Positioning this free offering in the same space with commercial companies doesn't seem to be a concern. "With our community helping us refine the boundaries, we think that over time we'll have the most complete and accurate set of boundary files available. As with open source software, you can get a lot more done with more people helping you than you can alone. We think the developer community will also be heavy users of the files since they can freely incorporate our boundaries into their product, versus having to pay a commercial firm for use."
Humphries addresses the licensing concerns by noting, "Zillow is interested in making sure that the largest number of people are able to make use of our data, and we'll continue to monitor our community to make sure that our license fulfills this goal."
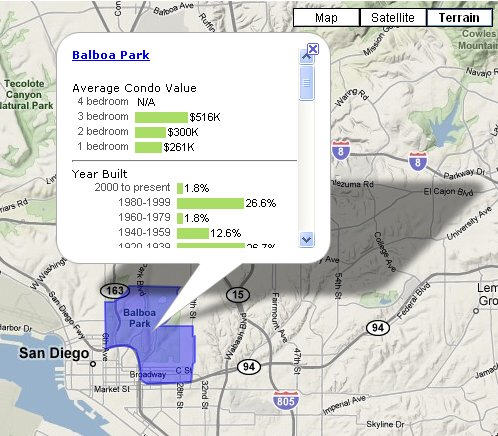 |
The Road Ahead
There's bound to be continued discussion of the nature of neighborhood boundaries, and other players are likely to join the fray. Adrian Holovaty, who's behind the new hyperlocal news site, EveryBlock, even notes an interest in such data, suggesting that site's readers may provide input.
From a geographic point of view, the definition of neighborhoods (or any sort of "mental maps" - for that's what these human perception boundaries often are) is fascinating. Unlike the quest for the "best" map of what's truly on the ground, which players such as Tele Atlas and NAVTEQ chase, this is a quest for something far more amorphous, but with quite a lot of value.
From Our Homepage
Saying Farewell to an Amazing Journey
Communicating with Maps
Is There a GIS Career Ladder?
What does it mean to be geospatially smart? Series
Ways Real Estate and Property Developers Utilize Melissa GeoData for Data-Driven Decisions
Unlocking Value From Daily Satellite Imagery and Insights
Maximizing the Value of Your Address Data with Geo Addressing
How Indoor Mapping Enhances the Security of Smart Buildings
Look Ahead: AI, Location Intelligence and Efficiency
Collaboration Takes on Sea Level Rise & Dynamic Technology Environments
Brownies for Brownfields
Has Everything Been Mapped Already?
How Is Data Literacy Changing in an Artificial Intelligence Landscape
Portfolios for GIS Professionals: More Than Just Maps
How to Create a Distance Matrix in QGIS - A Step-by-Step Guide
7 Ideas for Bringing GIS into the K-12 Classroom
The Geography of Movement