The choropleth
mapping technique, which uses "ranges" or "graduated color," is a type
of
thematic mapping that focuses usually on a single theme with data
summarized by
statistical or administrative areas.The name of this technique is
derived from
the Greek words choros - space, and pleth
- value.
The purpose of this article is to demonstrate how exploratory data analysis (EDA) can help in choosing the most appropriate method for creating choropleth maps. Although almost all types of analyses using geographically related data are exploratory, the term exploratory data analysis has a very specific meaning.EDA is a simple and relatively new approach (approximately 25 years old) developed in statistics.It involves testing whether the distribution of data is uniform or normal, and if there are any extreme values or outliers.EDA also incorporates visualizing and analyzing the patterns in distribution of data using such graphical tools as histograms, boxplots or the quantile-quantile (Q-Q) plots.Other typical EDA tools, not discussed in this article, include using factoring variables, stem-and-leaf plots, spread versus level plots or testing homogeneity of variances.
Statistical and geographical distributions
EDA should precede any other type of analysis.A histogram helps to visualize the statistical distribution of a given variable, whereas a map can help to understand its geographical distribution.These two tools (histogram and map) are related. Selecting the most appropriate mapping method depends on the histogram.
There are two statistical distributions that are most suitable for two mapping methods.The normal distribution is the most appropriate for using the standard deviation classification, whereas the uniform distribution is the most suitable for using the even class width classification.The uniform distribution is very rare in a real world.A variable having perfectly uniform distribution is not very interesting from the analytical point of view.Such a variable would have the same value in every record, the histogram would have all bars even, and a choropleth map would have all polygons shaded with the same color.The normal distribution is one of the most common in a real world.
The majority of variables, however, have irregular distributions not similar to either the uniform or normal ones.Normality tests show that only a few variables have normal distribution.The distribution depends on a sample size.For various sizes of the study area, the same variable can be normal or not, uniform or not. Also, excluding records (polygons) with zero values or missing values can alter results of statistical tests and shape of histograms.Statistical tests for normality or uniformity represent more precise tools than just analyzing histograms. Visual inspection of histograms is more subjective, although histograms show the whole spectrum of values for a given variable.
What data can be displayed using the choropleth technique?
There are two types of data summarized by areas: totals (or absolute values), such as, for example, total population, or derived values (or ratios), such as density of population or average value of dwelling.There is a general rule stating that unless areas have similar sizes, absolute values should not be used for the choropleth mapping.If absolute values are used for mapping areas that vary in size, misleading maps can be produced.
Ratios show the relationship between two quantities, and using them eliminates the influence of area, so that the map becomes meaningful by portraying accurately the distribution of features.The most commonly used ratios are averages, proportions (percentages) and densities.Some of the ratios are independent of area (spending on food as percent of total expenditure), others involve area in their calculation (population is divided by area to obtain the density of population).Data used for choropleth maps are then standardized in one or another way to allow the comparison of distributions across areas.
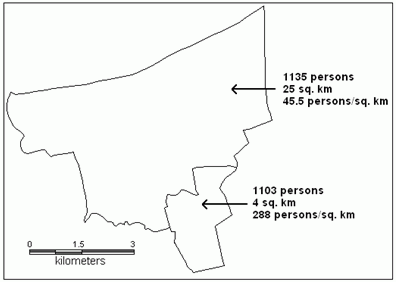
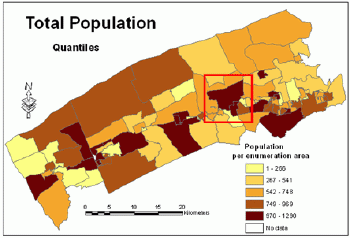
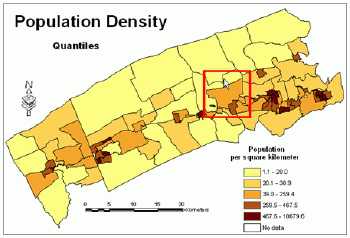
Figure 1 shows that a similar number of people live in two polygons, therefore they belong to the same class and are shaded using the same color.These polygons are marked in Figure 2 with the red box.The map in Figure 2 is of a very limited use because absolute values were used for its creation.Figure 3 shows that when relative values are used, the same polygons belong to two different classes and are shaded with different colors.The map in Figure 3 portrays appropriately the distribution of population within the study area.
Testing normality for the standard deviation classification scheme
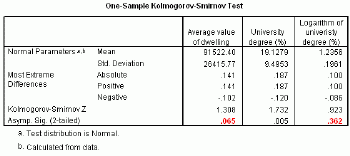
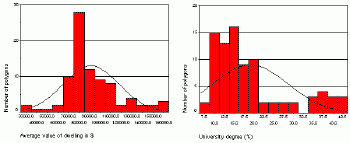
One of the most common tests for testing normality is the Kolmogorov-Smirnov test based on the maximum absolute difference between the standardized observed values and theoretical (normal) values for each record (polygon).This test, applied to many variables, indicates that the distribution of the average value of dwelling is normal but the distribution of people with university degree is not normal (Table 1, significance level > 0.05).However, if the last variable is transformed logarithmically, its distribution changes to normal.
The histogram is a visual tool for inspecting the statistical distribution.Comparison of two histograms indicates clearly that the average value of dwelling, but not the percentage of people with the university degree can be classified using the standard deviation classification scheme.
The standard deviation classification is based on the fact that in the normal distribution, 68.27% of data are within the arithmetic mean " one standard deviation interval; 95.45% of data are within the arithmetic mean " two standard deviations interval and 99.73% of data are within the arithmetic mean " three standard deviations interval.
A Q-Q plot is another graphical tool for inspecting normality.On Q-Q plots, the diagonal green line shows the ideal agreement between observed and expected (normal) data. Red dots represent polygons and their deviation from normality.Again, it is clear that the average value of dwelling has more normal distribution than the percentage of people with the university degree.
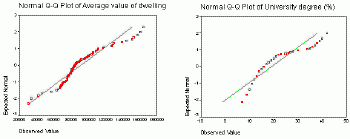
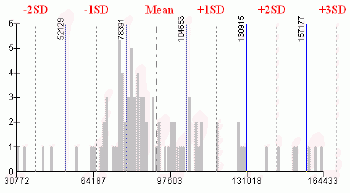
Figure 6 shows again the histogram for the average value of dwelling variable, but this time with marked class breaks.With this particular distribution, class breaks are defined based on the ±0.5, ±1.5 and outside of ±1.5 standard deviations from the mean value.
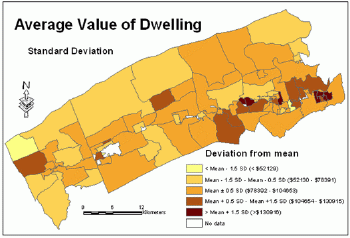
The map based on the standard deviation classification scheme does not show actual values for polygons but only which ones are above or below the mean value (Figure 7).
Testing uniformity for the equal interval classification scheme
The equal interval classification scheme for creating choropleth maps is recommended only if the statistical distribution of a mapped variable is uniform.The same Kolmogorov-Smirnov test can be used for this purpose.The idea is similar to testing normality, except that this time the expected distribution is uniform. Table 2 shows that the variable percent of female population is uniformly distributed with the significance level exceeding 0.05.Two other tested variables (unemployment rate and university degree) are not distributed uniformly.Therefore, the percent of female population is the only variable of the three tested that can be classified using the equal interval (known also as equal step or equal range) classification scheme.The histogram in Figure 8 also confirms that the distribution of this variable is rather uniform (rectangular shape).

The equal interval is computed by dividing the difference between the highest and lowest value by the number of classes.The received number (interval) is then added to the lowest data value to get the upper class limit for the first class.It is then added to each upper class limit of the previous class to determine breaks for the remaining classes until the highest value is reached.Figure 9 shows class breaks for the analyzed variable.
The map (Figure 10) created with the equal interval classification scheme is easy to interpret since the width of each class is equal.This method is especially useful when enumeration areas are nearly equal in size.
For certain data types, however, this mapping technique may be disadvantageous, because it can produce classes with few or no features contained in them.
Quantiles and natural breaks classification schemes
The standard deviation and equal interval classification schemes are two of the four commonly used standard classification schemes.The other two are the quantiles and the natural breaks methods.
Quantiles represent a classification of data in which each class contains a similar number of units (records, polygons).The data set can be divided into any number of classes that have variable width.If the entire data set is divided into halves, the class break is a median.Dividing data into four classes produces quartiles separated by three class breaks.The other quantiles include quintiles (five classes with four class breaks), deciles (ten classes with nine class breaks), and percentiles (one hundred classes with ninety nine class breaks).The positions of class breaks can be calculated using the following formula:
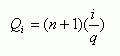
where Qi
is a position of ith class break, q represents the type of quantiles
(median, quartiles, quintiles, deciles, percentiles), i
varies from 1 to (q - 1)
and n is a number of polygons.
For example, if there are 25 polygons in the study area and they have to be classified using quartiles (q = 4, i = 1, 2, 3), the position of class breaks can be calculated as follows:
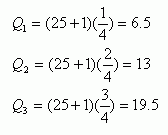
When positions of quantiles are known, the corresponding values can easily be obtained from the data set ordered in the ascending order.
One of the disadvantages of the quantiles method is that in order to get an equal number of enumeration areas in each class, areas with very different values may be placed in the same class.
The natural breaks classification scheme also produces variable class width, but class breaks are defined differently.They are placed where there are gaps between clusters of values.
Normality and uniformity tests indicated that the variable unemployment rate has neither normal nor uniform distribution.The histogram in Figure 11 shows that this variable has uneven distribution.Both quantiles and natural breaks classification schemes could be applied for mapping the unemployment rate.Figures 11 and 12 illustrate that both methods classify this variable similarly.Visual examination of histograms and maps (Figures 13 and 14) would not indicate which method is better.Considering the fact that the natural breaks classification scheme used to produce maps for this paper incorporates the Jenks' optimization method (ensuring maximum homogeneity within groups and maximum heterogeneity between groups), it is possible to assume that the natural breaks classification scheme is better for this particular variable.
Comparing classification schemes
Figures 7, 15, 16 and 17 show the distribution of the average value of dwelling mapped using all four classification schemes.Knowing that this variable has normal distribution and the standard deviation classification is the most suitable for mapping this distribution, an attempt was made to compare the results of mapping this variable with other classification schemes.Some cartographers believe that more than one map should be made for a particular data set to allow the reader to compare them.
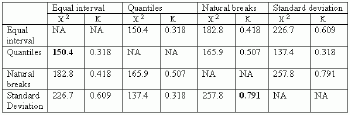
All classification schemes have five numeric classes plus one category, "No data." Each polygon was classified four times for four different choropleth maps.Using cross-tabulation, a 4x4 contingency table (Table 3) was created with some statistics showing association and agreement between the classification schemes. This comparison is based on the number of polygons belonging to every class in each classification scheme. Every pair of two schemes was analyzed in terms or whether they are dependent.The chi-square statistic was used for this purpose.The following symmetric table presents six chi-square statistics (c2). All of them are very significant indicating that classification schemes are related.The strongest relationship exists between the equal interval and quantiles classifications (the smallest value of chi-square) whereas the natural breaks and standard deviation are related not so strongly (the highest value of chi-square), although still significantly.
Additionally, the kappa statistic (K) was used to measure the strength of agreement between classification schemes.All values of kappa indicate the significant agreement between all classification schemes.It is assumed that if the kappa value is higher than 0.75, the agreement is excellent, as for the standard deviation and natural breaks classification schemes.If the kappa value is between 0.4 and 0.75 the agreement is fair and three other pairs of classifications are within this range.
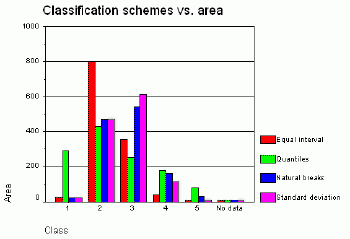
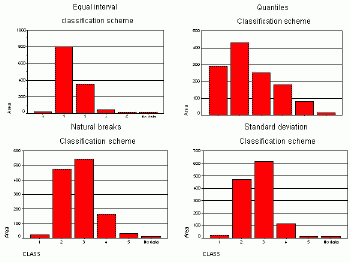
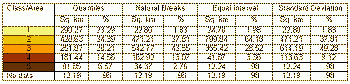
When classification schemes are compared by calculating the area of polygons belonging to every class in each classification scheme, the results are analogous.As it can be seen in Figures 18, 19 and Table 4, the standard deviation and natural breaks methods classified the variable average value of dwelling similarly.The other two methods produced very dissimilar results.
Analyzing outliers and extreme values
Outliers and extremes represent irregularity in data sets.Their presence should be detected and explained.In some situations, they also can be excluded and mapped as a category called "Others." In exploratory data analysis, boxplots are used for visualizing outliers and extremes.
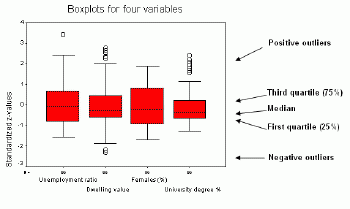
Figure 20 presents boxplots for the four variables.Original values for these variables had different ranges.Three of them had values between 0 and 100 and the average value of dwelling was close to 100,000.In order to bring all these values to the common denominator, these variables were transformed (standardized) to so-called z values by subtracting arithmetic mean from original values and then dividing the difference by a standard deviation.As the result z-values have new values mostly within the range from -3 to +3.
The boxplot consists of the central red rectangle representing the spread of 50% of data around the median.The top of this rectangle corresponds to the value of 75% of data (third quartile).The bottom of the rectangle corresponds to the value of 25% of data (first quartile).The rectangle height represents the difference between the third and first quartiles and is called the interquartile range.As it can be seen, the percentage of females has the widest spread of the middle 50% of data, whereas the university degree represents the smallest spread.The horizontal bar inside the red rectangle represents the median.Horizontal lines outside the red rectangle show the interval where values are not classified as outliers or extremes.Outliers are shown as circles.They can be positive (above the box) or negative (below the box) and they have values greater than 1.5 of the rectangle height added to the third quartile (for positive outliers) or subtracted from the first quartile (for negative outliers).Figure 20 illustrates that there are positive outliers for three variables and negative outliers for one variable.The variable Females (%) does not have outliers at all.In addition to outliers, there can be positive or negative extremes extending the value of three interquartile ranges above the third quartile and below the first quartile.None of the analyzed variables has extremes. Eliminating outliers and extremes (for example, negative outliers or extremes for zero representing no data), can change radically the distribution of a variable.
The purpose of this article is to demonstrate how exploratory data analysis (EDA) can help in choosing the most appropriate method for creating choropleth maps. Although almost all types of analyses using geographically related data are exploratory, the term exploratory data analysis has a very specific meaning.EDA is a simple and relatively new approach (approximately 25 years old) developed in statistics.It involves testing whether the distribution of data is uniform or normal, and if there are any extreme values or outliers.EDA also incorporates visualizing and analyzing the patterns in distribution of data using such graphical tools as histograms, boxplots or the quantile-quantile (Q-Q) plots.Other typical EDA tools, not discussed in this article, include using factoring variables, stem-and-leaf plots, spread versus level plots or testing homogeneity of variances.
Statistical and geographical distributions
EDA should precede any other type of analysis.A histogram helps to visualize the statistical distribution of a given variable, whereas a map can help to understand its geographical distribution.These two tools (histogram and map) are related. Selecting the most appropriate mapping method depends on the histogram.
There are two statistical distributions that are most suitable for two mapping methods.The normal distribution is the most appropriate for using the standard deviation classification, whereas the uniform distribution is the most suitable for using the even class width classification.The uniform distribution is very rare in a real world.A variable having perfectly uniform distribution is not very interesting from the analytical point of view.Such a variable would have the same value in every record, the histogram would have all bars even, and a choropleth map would have all polygons shaded with the same color.The normal distribution is one of the most common in a real world.
The majority of variables, however, have irregular distributions not similar to either the uniform or normal ones.Normality tests show that only a few variables have normal distribution.The distribution depends on a sample size.For various sizes of the study area, the same variable can be normal or not, uniform or not. Also, excluding records (polygons) with zero values or missing values can alter results of statistical tests and shape of histograms.Statistical tests for normality or uniformity represent more precise tools than just analyzing histograms. Visual inspection of histograms is more subjective, although histograms show the whole spectrum of values for a given variable.
What data can be displayed using the choropleth technique?
There are two types of data summarized by areas: totals (or absolute values), such as, for example, total population, or derived values (or ratios), such as density of population or average value of dwelling.There is a general rule stating that unless areas have similar sizes, absolute values should not be used for the choropleth mapping.If absolute values are used for mapping areas that vary in size, misleading maps can be produced.
Ratios show the relationship between two quantities, and using them eliminates the influence of area, so that the map becomes meaningful by portraying accurately the distribution of features.The most commonly used ratios are averages, proportions (percentages) and densities.Some of the ratios are independent of area (spending on food as percent of total expenditure), others involve area in their calculation (population is divided by area to obtain the density of population).Data used for choropleth maps are then standardized in one or another way to allow the comparison of distributions across areas.
Figure 1 shows that a similar number of people live in two polygons, therefore they belong to the same class and are shaded using the same color.These polygons are marked in Figure 2 with the red box.The map in Figure 2 is of a very limited use because absolute values were used for its creation.Figure 3 shows that when relative values are used, the same polygons belong to two different classes and are shaded with different colors.The map in Figure 3 portrays appropriately the distribution of population within the study area.
Figure 1.Absolute and
derived values for varying size enumeration areas.
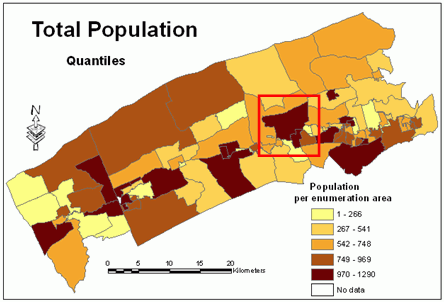
Figure 2.Population
- absolute values. Click image for larger view.
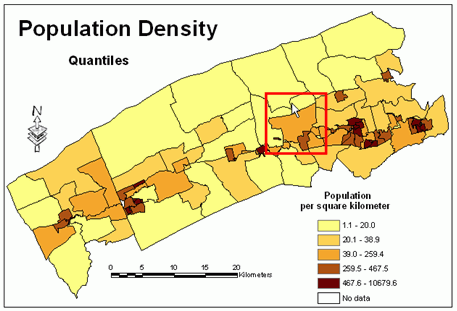
Figure 3.Population
density.Click image for larger view.
Testing normality for the standard deviation classification scheme
One of the most common tests for testing normality is the Kolmogorov-Smirnov test based on the maximum absolute difference between the standardized observed values and theoretical (normal) values for each record (polygon).This test, applied to many variables, indicates that the distribution of the average value of dwelling is normal but the distribution of people with university degree is not normal (Table 1, significance level > 0.05).However, if the last variable is transformed logarithmically, its distribution changes to normal.

Table 1.One-Sample
Kolmogorow-Smirnov Test. Click image for larger view.
The histogram is a visual tool for inspecting the statistical distribution.Comparison of two histograms indicates clearly that the average value of dwelling, but not the percentage of people with the university degree can be classified using the standard deviation classification scheme.
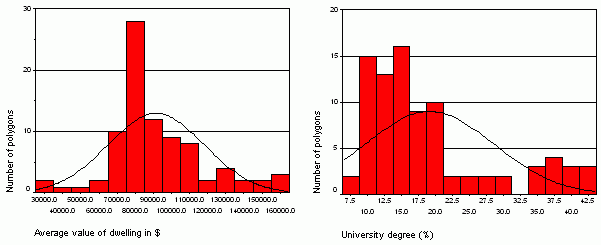
Figure 4.Histograms
for two variables: average value of dwelling and percent of people with
the
university degree.Click image for larger view.
The standard deviation classification is based on the fact that in the normal distribution, 68.27% of data are within the arithmetic mean " one standard deviation interval; 95.45% of data are within the arithmetic mean " two standard deviations interval and 99.73% of data are within the arithmetic mean " three standard deviations interval.
A Q-Q plot is another graphical tool for inspecting normality.On Q-Q plots, the diagonal green line shows the ideal agreement between observed and expected (normal) data. Red dots represent polygons and their deviation from normality.Again, it is clear that the average value of dwelling has more normal distribution than the percentage of people with the university degree.
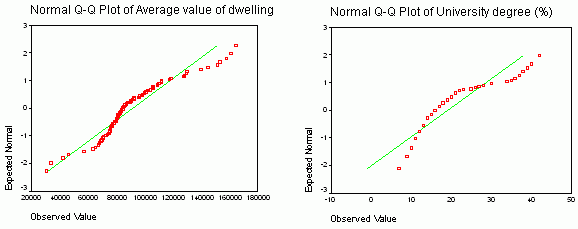
Figure 5.Q-Q plots
for two variables: average value of dwelling and percent of people with
the
university degree.Click image for larger view.
Figure 6 shows again the histogram for the average value of dwelling variable, but this time with marked class breaks.With this particular distribution, class breaks are defined based on the ±0.5, ±1.5 and outside of ±1.5 standard deviations from the mean value.

Figure 6.Histogram
for the average value of dwelling variable with marked class breaks.Click
image for larger view.
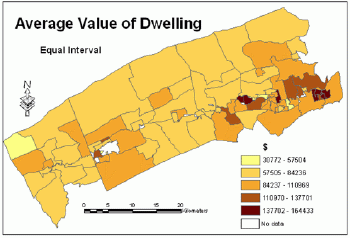
The map based on the standard deviation classification scheme does not show actual values for polygons but only which ones are above or below the mean value (Figure 7).
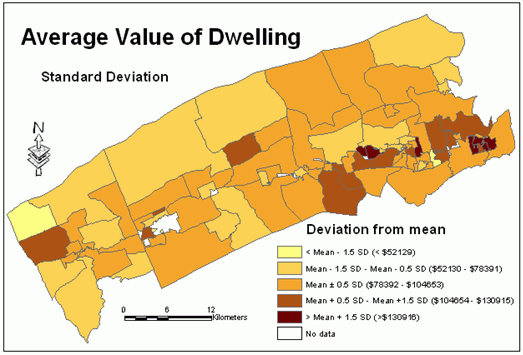
Figure 7.Average
value of dwelling - standard deviation classification method.Click
image for larger view.
Testing uniformity for the equal interval classification scheme
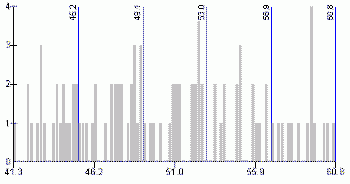
The equal interval classification scheme for creating choropleth maps is recommended only if the statistical distribution of a mapped variable is uniform.The same Kolmogorov-Smirnov test can be used for this purpose.The idea is similar to testing normality, except that this time the expected distribution is uniform. Table 2 shows that the variable percent of female population is uniformly distributed with the significance level exceeding 0.05.Two other tested variables (unemployment rate and university degree) are not distributed uniformly.Therefore, the percent of female population is the only variable of the three tested that can be classified using the equal interval (known also as equal step or equal range) classification scheme.The histogram in Figure 8 also confirms that the distribution of this variable is rather uniform (rectangular shape).
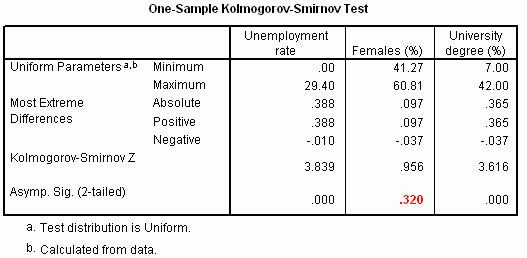
Table 2.One-Sample
Kolmogorow-Smirnov Test.Click image for larger view.
Figure 8.Histogram
for the percent of female population in the total population.
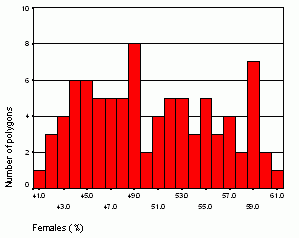
The equal interval is computed by dividing the difference between the highest and lowest value by the number of classes.The received number (interval) is then added to the lowest data value to get the upper class limit for the first class.It is then added to each upper class limit of the previous class to determine breaks for the remaining classes until the highest value is reached.Figure 9 shows class breaks for the analyzed variable.
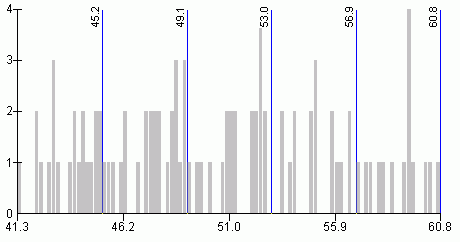
Figure 9.Histogram
for the percentage of female population in the total population with
marked
class breaks. Click image for larger view.
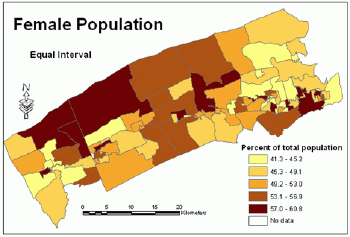
The map (Figure 10) created with the equal interval classification scheme is easy to interpret since the width of each class is equal.This method is especially useful when enumeration areas are nearly equal in size.
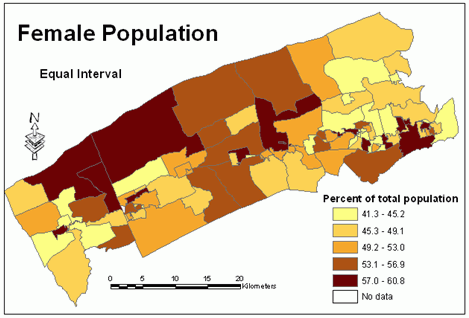
Figure 10.Percentage
of female population in the total population - equal interval
classification
method. Click image for larger view.
For certain data types, however, this mapping technique may be disadvantageous, because it can produce classes with few or no features contained in them.
Quantiles and natural breaks classification schemes
The standard deviation and equal interval classification schemes are two of the four commonly used standard classification schemes.The other two are the quantiles and the natural breaks methods.
Quantiles represent a classification of data in which each class contains a similar number of units (records, polygons).The data set can be divided into any number of classes that have variable width.If the entire data set is divided into halves, the class break is a median.Dividing data into four classes produces quartiles separated by three class breaks.The other quantiles include quintiles (five classes with four class breaks), deciles (ten classes with nine class breaks), and percentiles (one hundred classes with ninety nine class breaks).The positions of class breaks can be calculated using the following formula:
For example, if there are 25 polygons in the study area and they have to be classified using quartiles (q = 4, i = 1, 2, 3), the position of class breaks can be calculated as follows:
When positions of quantiles are known, the corresponding values can easily be obtained from the data set ordered in the ascending order.
One of the disadvantages of the quantiles method is that in order to get an equal number of enumeration areas in each class, areas with very different values may be placed in the same class.
The natural breaks classification scheme also produces variable class width, but class breaks are defined differently.They are placed where there are gaps between clusters of values.
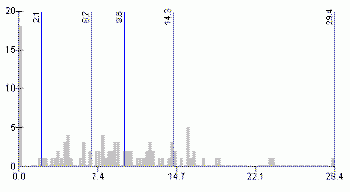
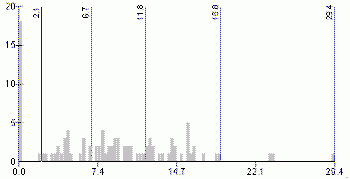
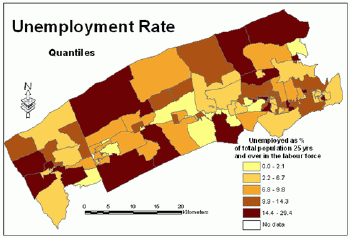
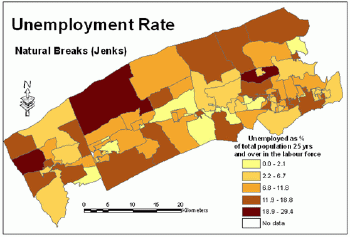
Normality and uniformity tests indicated that the variable unemployment rate has neither normal nor uniform distribution.The histogram in Figure 11 shows that this variable has uneven distribution.Both quantiles and natural breaks classification schemes could be applied for mapping the unemployment rate.Figures 11 and 12 illustrate that both methods classify this variable similarly.Visual examination of histograms and maps (Figures 13 and 14) would not indicate which method is better.Considering the fact that the natural breaks classification scheme used to produce maps for this paper incorporates the Jenks' optimization method (ensuring maximum homogeneity within groups and maximum heterogeneity between groups), it is possible to assume that the natural breaks classification scheme is better for this particular variable.
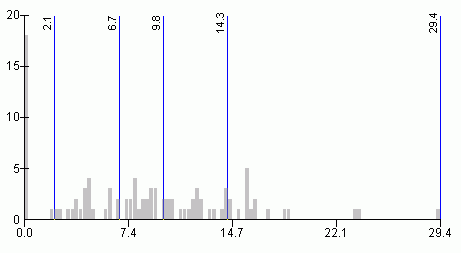
Figure 11.Histogram
and class breaks for the unemployment rate variable - quantiles
classification
method.Click image for larger view.
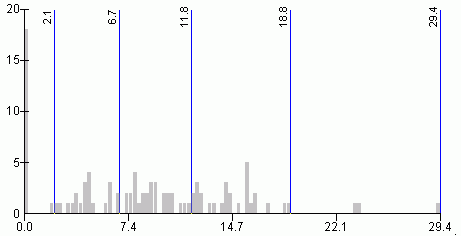
Figure 12.Histogram
and class breaks for the unemployment rate variable - natural breaks
classification method. Click image for larger view.
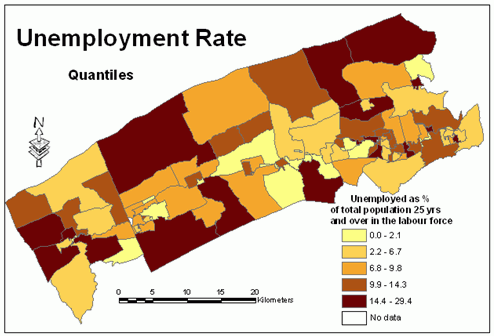
Figure 13.
Unemployment
rate - quantiles classification method. Click image for larger view.
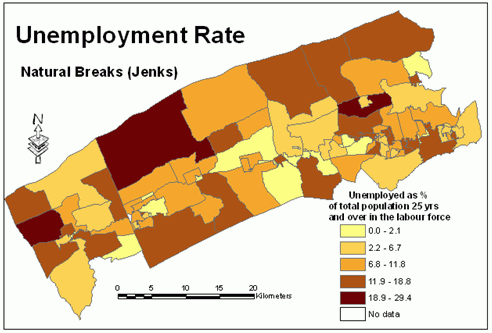
Figure 14.
Unemployment
rate - natural breaks classification method. Click image for larger
view.
Comparing classification schemes
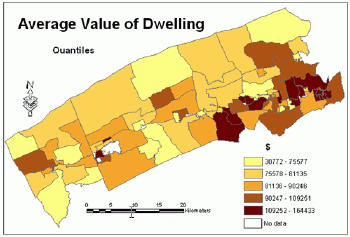
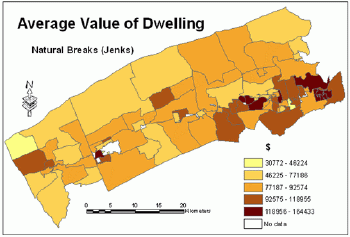
Figures 7, 15, 16 and 17 show the distribution of the average value of dwelling mapped using all four classification schemes.Knowing that this variable has normal distribution and the standard deviation classification is the most suitable for mapping this distribution, an attempt was made to compare the results of mapping this variable with other classification schemes.Some cartographers believe that more than one map should be made for a particular data set to allow the reader to compare them.
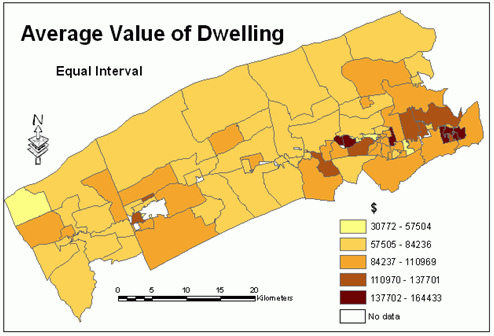
Figure 15.Average
value of dwelling - equal interval classification method.Click
image for larger view.
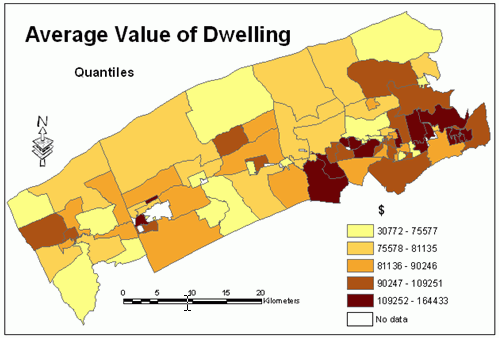
Figure 16.Average
value of dwelling - quantiles classification method. Click image for
larger view.
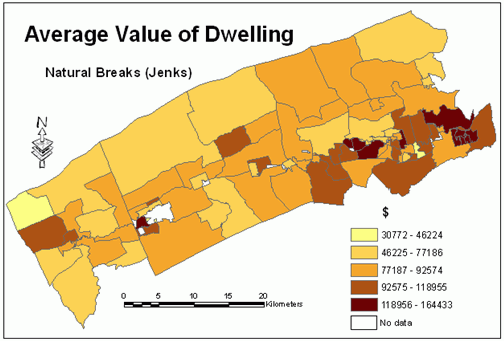
Figure 17.Average
value of dwelling - natural breaks classification method (Jenks).Click
image for larger view.
All classification schemes have five numeric classes plus one category, "No data." Each polygon was classified four times for four different choropleth maps.Using cross-tabulation, a 4x4 contingency table (Table 3) was created with some statistics showing association and agreement between the classification schemes. This comparison is based on the number of polygons belonging to every class in each classification scheme. Every pair of two schemes was analyzed in terms or whether they are dependent.The chi-square statistic was used for this purpose.The following symmetric table presents six chi-square statistics (c2). All of them are very significant indicating that classification schemes are related.The strongest relationship exists between the equal interval and quantiles classifications (the smallest value of chi-square) whereas the natural breaks and standard deviation are related not so strongly (the highest value of chi-square), although still significantly.
Additionally, the kappa statistic (K) was used to measure the strength of agreement between classification schemes.All values of kappa indicate the significant agreement between all classification schemes.It is assumed that if the kappa value is higher than 0.75, the agreement is excellent, as for the standard deviation and natural breaks classification schemes.If the kappa value is between 0.4 and 0.75 the agreement is fair and three other pairs of classifications are within this range.
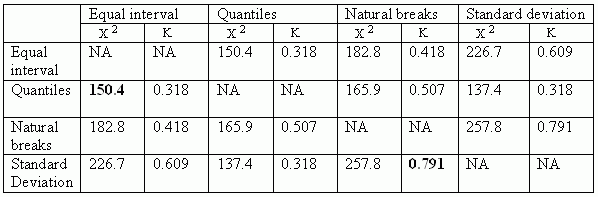
Table 3.
Correspondence between classification schemes (for the variable average
value
of dwelling $).Click image for larger view.
When classification schemes are compared by calculating the area of polygons belonging to every class in each classification scheme, the results are analogous.As it can be seen in Figures 18, 19 and Table 4, the standard deviation and natural breaks methods classified the variable average value of dwelling similarly.The other two methods produced very dissimilar results.
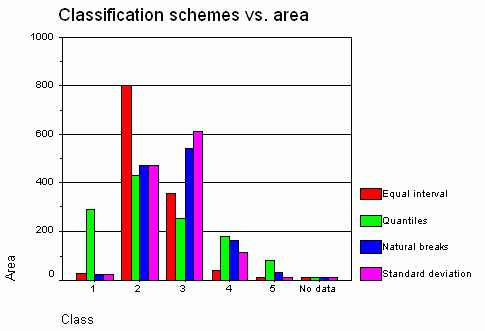
Figure 18.
Classification schemes vs.area. Click image for larger view.

Figure 19.
Classification
schemes vs.area.Click image for larger view.
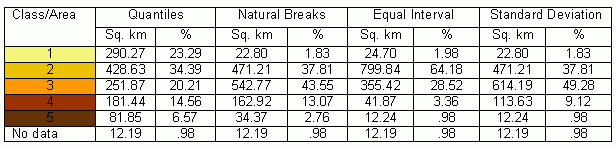
Table 4.Summary of
classification results (for the variable average value of dwelling $).
Click image for larger view.
Analyzing outliers and extreme values
Outliers and extremes represent irregularity in data sets.Their presence should be detected and explained.In some situations, they also can be excluded and mapped as a category called "Others." In exploratory data analysis, boxplots are used for visualizing outliers and extremes.
Figure 20 presents boxplots for the four variables.Original values for these variables had different ranges.Three of them had values between 0 and 100 and the average value of dwelling was close to 100,000.In order to bring all these values to the common denominator, these variables were transformed (standardized) to so-called z values by subtracting arithmetic mean from original values and then dividing the difference by a standard deviation.As the result z-values have new values mostly within the range from -3 to +3.
The boxplot consists of the central red rectangle representing the spread of 50% of data around the median.The top of this rectangle corresponds to the value of 75% of data (third quartile).The bottom of the rectangle corresponds to the value of 25% of data (first quartile).The rectangle height represents the difference between the third and first quartiles and is called the interquartile range.As it can be seen, the percentage of females has the widest spread of the middle 50% of data, whereas the university degree represents the smallest spread.The horizontal bar inside the red rectangle represents the median.Horizontal lines outside the red rectangle show the interval where values are not classified as outliers or extremes.Outliers are shown as circles.They can be positive (above the box) or negative (below the box) and they have values greater than 1.5 of the rectangle height added to the third quartile (for positive outliers) or subtracted from the first quartile (for negative outliers).Figure 20 illustrates that there are positive outliers for three variables and negative outliers for one variable.The variable Females (%) does not have outliers at all.In addition to outliers, there can be positive or negative extremes extending the value of three interquartile ranges above the third quartile and below the first quartile.None of the analyzed variables has extremes. Eliminating outliers and extremes (for example, negative outliers or extremes for zero representing no data), can change radically the distribution of a variable.
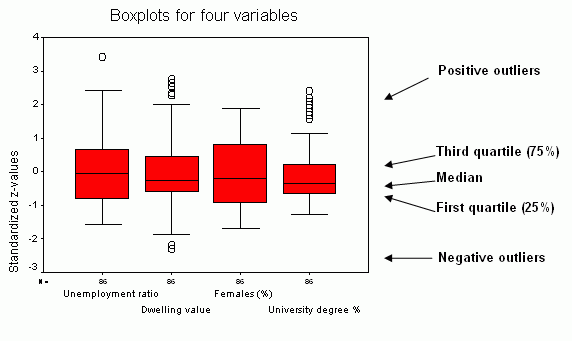
Figure 20.Boxplots
for selected variables. Click image for larger
view.
From Our Homepage
Saying Farewell to an Amazing Journey
Communicating with Maps
Is There a GIS Career Ladder?
What does it mean to be geospatially smart? Series
Ways Real Estate and Property Developers Utilize Melissa GeoData for Data-Driven Decisions
Unlocking Value From Daily Satellite Imagery and Insights
Maximizing the Value of Your Address Data with Geo Addressing
How Indoor Mapping Enhances the Security of Smart Buildings
Look Ahead: AI, Location Intelligence and Efficiency
Collaboration Takes on Sea Level Rise & Dynamic Technology Environments
Brownies for Brownfields
Has Everything Been Mapped Already?
How Is Data Literacy Changing in an Artificial Intelligence Landscape
Portfolios for GIS Professionals: More Than Just Maps
How to Create a Distance Matrix in QGIS - A Step-by-Step Guide
7 Ideas for Bringing GIS into the K-12 Classroom
The Geography of Movement