Geoparsing
offers the promise of modern geospatial alchemy... the ability to turn
text documents into geospatial databases. This "magic" is done in two
steps: 1) entity extraction and 2) disambiguation, which is also known
as grounding or geotagging. Geospatial entity extraction uses natural
language processing to identify place names in text, while
disambiguation associates a name with its correct location. The
geoparsing results can be inserted into the original document, used to
produce a new document, or formatted for output to a geospatial
application.
Geoparsing is most frequently used to automatically analyze collections of text documents. There are a number of commercial products with a geoparsing capability. Companies like MetaCarta extract information about place and time, while others like Digital Reasoning (GeoLocator), Lockheed Martin (AeroText), and SRA (NetOwl) extract places along with other entities, such as persons, organizations, time, money, etc. To process the large volumes of data, these systems rely on automated techniques optimized for speed.
Users of these automated systems understand that geoparsing is not perfect. Identifying and disambiguating place names in text are difficult and vulnerable to the vagaries of language. Just identifying which words are associated with place names can be a challenge. Take the example of the sentence, "The cat lay down to rest." Each word in the sentence is a valid place name in the National Geospatial-Intelligence Agency gazetteer! The geoparsing software must not only understand the words, but whether the words that form a name actually refer to a place. The software must understand that Paris in Paris, France refers to an urban area; in Paris Creek refers to a stream; in Paris Hilton refers to a person; and in Paris Match refers to a magazine name.
Once a place name has been identified, disambiguation remains a challenge. For example, there are over 2,100 names in the National Geospatial-Intelligence Agency which exactly match San Antonio. Knowing which San Antonio is the correct one requires additional context. Sometimes, without being the author of a document, it is simply not possible to identify, with any confidence, the place to which a name refers.
Given these difficulties, it is understandable that automated geoparsing software will miss some place names, identify non-place text as place names, and sometimes identify the location of place incorrectly if multiple choices are possible.
Recently, the US Army Topographic Engineering Center (USATEC), Engineer Research and Development Center (ERDC) teamed with Stottler Henke Associates under the US Army Small Business Innovative Research Program to develop a new and innovative approach to geoparsing (beta here). Rather than focus on analyzing collections of documents, Stottler Henke's GeoDoc framework focuses on the individual document, allowing authors to efficiently ensure that the place names are identified correctly and are discoverable by other users. Just as map documents go through a review and validation process, this approach allows authors to confirm that the places in their documents are correctly identified and located at the time of writing.
This has been accomplished through the tight integration of automated geoparsing techniques with place checking software that allows users to edit place names very rapidly and then output them for the Web using Microformats. Microformats encode place names and coordinates in a format that can be discovered by other applications.
Place Checking
Document level geoparsing begins with a user loading a text document or Web page into the GeoDoc application. Rather than forcing the user to identify and tag the place names manually, the application starts by automatically extracting place names and highlighting them on the display. Up to this point, the processing resembles other geoparsing systems.
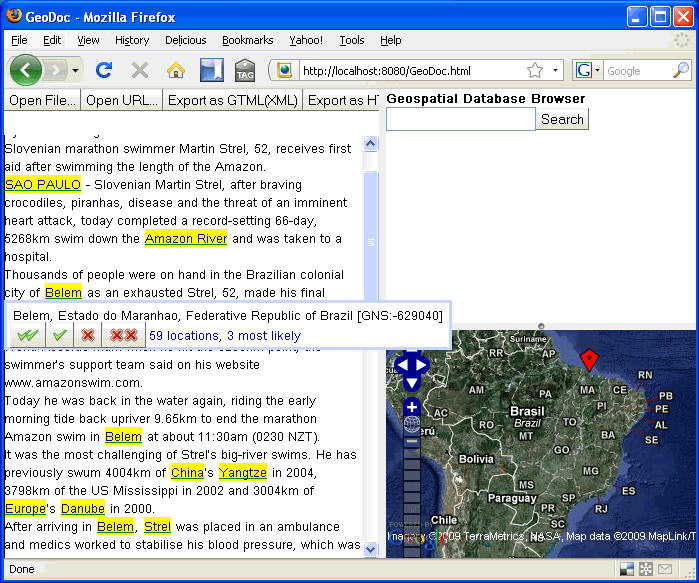
Once potential place names have been extracted and highlighted, the user begins the place checking step. This is accomplished by rapidly stepping through the highlighted names in the document. When the cursor is hovered over a name, the system shows the most likely name and offers the opportunity to accept or reject one or all occurrences of the name.
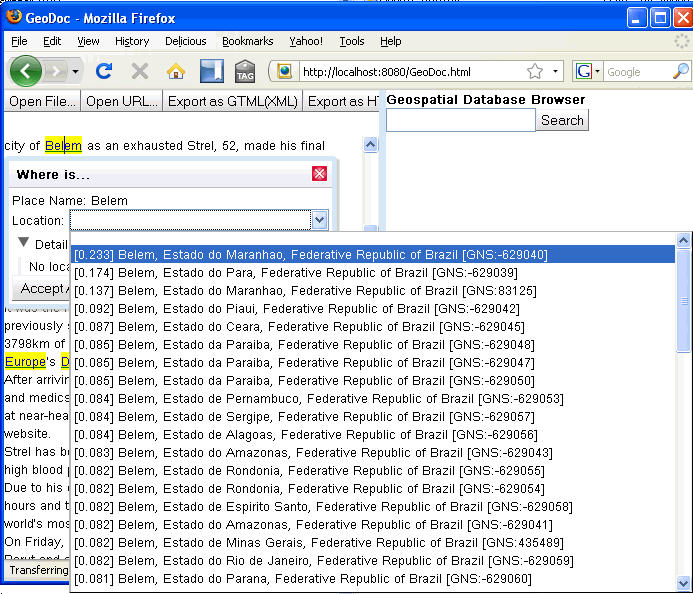
Clicking on the name displays a ranked list of names that could potentially refer to the name. Names which are higher on the list represent more likely candidates. In the sentence, "There was a tornado in Paris, Texas," Paris, Texas will be rated higher than Paris, France because the additional qualifier, Texas, is present. If the suggested name is not the name of interest, the user simply selects the correct name. After the correct name is identified, the user can accept the individual name or all occurrences of the name in the document.
Names which are not found can be looked up in the Stottler Henke gazetteer, which includes U.S. and foreign place names, as well as common abbreviations and aliases. If no name is found, the user can mark the name as a place name without recording the coordinates. These can then be hand-edited.
According to T.J. Goan, the Stottler Henke project manager, "This process revolutionizes document-level geoparsing. Following the model for spell checking used by word processing programs, we have integrated a simple and straightforward process to validate the place names and locations. Users can quickly check the place names to verify that all entries meet their requirements and are correctly tagged."
Geoparsing and Microformats
Microformats make information about people, organizations, places, events, opinions, ratings and reviews discoverable by other applications. The power in this approach is that new applications can search tagged documents, discover geospatial content and incorporate this in new mashups. Given the geospatial information contained in the tags, users can automatically generate maps, charts or tables to accompany the text. In addition they can link the content to other information to create totally new content. The applications using the tags may or may not be known to the authors of the documents, providing greater reuse and value to the community.
Dave Dearing, the GeoDoc lead software developer, noted, "This approach is in keeping with the Web philosophy of tagging, then sharing; rather than sharing and then tagging. Most existing geoparsing products follow the latter approach."
Microformats are machine-readable, semantic mark-up formats that are gaining in popularity. They are human-readable and built upon widely adopted standards. Most importantly, the Stottler Henke Associates' geoparsing process embeds Microformats non-destructively in the original text. This allows a user to input a Web page, edit the place names on the page, and output a product that looks like the original page, but contains the semantic information about the mentioned places.
Two of the draft Microformats, the Geo and adr, are relevant for encoding geographic information. The Geo format stores World Geodetic System (WGS) 84 geographic coordinates, while the adr is used to store address information. The adr format is not limited to street addressing, but can address higher level places, such as cities, states and countries which would commonly be found in a gazetteer. Both are suitable for embedding location information in HTML, XHTML, Atom, RSS or arbitrary XML.
Dearing demonstrated the power of geoparsing with Microformats to users by interactively editing a geotagged document using their Web application and then opening a geotagged document in the Firefox browser with the Operator Add-In.
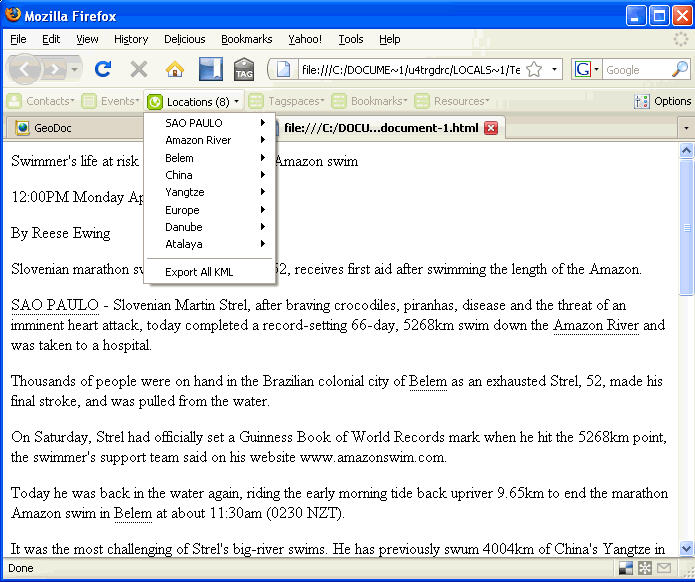
Operator automatically detects Microformats related to contacts, events, locations, tagspaces, bookmarks and resources.
He opened a Web page that showed all the original information, with the addition that place names were now underlined. Coordinates were displayed when he hovered the cursor over the name. The place names were identified as locations in the Operator toolbar. The user could select a location and view it in Google Maps, MapQuest or Yahoo! Maps, or export an individual name or all the place names to the Keyhole Markup Language (KML) for display in a variety of applications.
Dearing observed, "Operator is a tool that discovers and exploits Microformats. Working with Operator is a good way for users to begin to explore the potential for semantic tagging and requires no additional development."
Microformats are not the only format available for geospatial semantic tagging. Other formats, like the Resource Description Framework (RDF) or community-based tagging systems, offer alternatives. However, at this point Microformats are widely used and readily available, with simple tools in place to exploit the information.
Aaron Novstrup, a GeoDoc Web developer at Stottler Henke, observed, "From a programming perspective, Microformats are quick and simple to implement and are easy to exploit. They represent a good first step for developers and users. Our GeoDoc framework is flexible and will easily accommodate other semantic tagging standards as they evolve and we currently offer a Geography Markup Language (GML)-based output as well."
Geoparsing applications will continue to evolve and develop rapidly in the near future, as the ability to extract and tag places improves. There will always be a place for document-level place checking and the use of semantic tagging to support the discovery and exploitation of place names in text.
The Way Ahead
Stottler Henke's GeoDoc application demonstrates two key components of the future of geoparsing: interactive editing and semantic tagging. Military users will not only want to exploit automatically geoparsed documents, they will require a capability to efficiently edit the results to certify that the place names in the document are all geotagged, and geotagged correctly. Just as cartographers review and validate map content prior to publication, geospatial analysts will review and validate geotagged text documents. Place checking, like spell checking, allows users to quickly and easily edit the content of their documents.
GeoDoc produces semantically tagged documents, which contain information that can be discovered and exploited by other applications, which can mashup the data with other Web content. The application currently outputs to a GML format, as well as a Microformat-based output. The Microformat output non-destructively inserts tags in the original document that are recognized by applications such as Operator, a Foxfire add-on. With the recognition of the importance of semantically tagged content, military organizations and government agencies will increasingly incorporate tags with their published content. Users who discover and exploit this information will be able to automatically generate maps, charts and tables related to the text, as well as mash-up the geospatial content with other information.
Resources
Stottler Henke Associates
US Army Engineer Research and Development Center
Microformats
Geoparsing is most frequently used to automatically analyze collections of text documents. There are a number of commercial products with a geoparsing capability. Companies like MetaCarta extract information about place and time, while others like Digital Reasoning (GeoLocator), Lockheed Martin (AeroText), and SRA (NetOwl) extract places along with other entities, such as persons, organizations, time, money, etc. To process the large volumes of data, these systems rely on automated techniques optimized for speed.
Users of these automated systems understand that geoparsing is not perfect. Identifying and disambiguating place names in text are difficult and vulnerable to the vagaries of language. Just identifying which words are associated with place names can be a challenge. Take the example of the sentence, "The cat lay down to rest." Each word in the sentence is a valid place name in the National Geospatial-Intelligence Agency gazetteer! The geoparsing software must not only understand the words, but whether the words that form a name actually refer to a place. The software must understand that Paris in Paris, France refers to an urban area; in Paris Creek refers to a stream; in Paris Hilton refers to a person; and in Paris Match refers to a magazine name.
Once a place name has been identified, disambiguation remains a challenge. For example, there are over 2,100 names in the National Geospatial-Intelligence Agency which exactly match San Antonio. Knowing which San Antonio is the correct one requires additional context. Sometimes, without being the author of a document, it is simply not possible to identify, with any confidence, the place to which a name refers.
Given these difficulties, it is understandable that automated geoparsing software will miss some place names, identify non-place text as place names, and sometimes identify the location of place incorrectly if multiple choices are possible.
Recently, the US Army Topographic Engineering Center (USATEC), Engineer Research and Development Center (ERDC) teamed with Stottler Henke Associates under the US Army Small Business Innovative Research Program to develop a new and innovative approach to geoparsing (beta here). Rather than focus on analyzing collections of documents, Stottler Henke's GeoDoc framework focuses on the individual document, allowing authors to efficiently ensure that the place names are identified correctly and are discoverable by other users. Just as map documents go through a review and validation process, this approach allows authors to confirm that the places in their documents are correctly identified and located at the time of writing.
This has been accomplished through the tight integration of automated geoparsing techniques with place checking software that allows users to edit place names very rapidly and then output them for the Web using Microformats. Microformats encode place names and coordinates in a format that can be discovered by other applications.
Place Checking
Document level geoparsing begins with a user loading a text document or Web page into the GeoDoc application. Rather than forcing the user to identify and tag the place names manually, the application starts by automatically extracting place names and highlighting them on the display. Up to this point, the processing resembles other geoparsing systems.
Once potential place names have been extracted and highlighted, the user begins the place checking step. This is accomplished by rapidly stepping through the highlighted names in the document. When the cursor is hovered over a name, the system shows the most likely name and offers the opportunity to accept or reject one or all occurrences of the name.
 |
Clicking on the name displays a ranked list of names that could potentially refer to the name. Names which are higher on the list represent more likely candidates. In the sentence, "There was a tornado in Paris, Texas," Paris, Texas will be rated higher than Paris, France because the additional qualifier, Texas, is present. If the suggested name is not the name of interest, the user simply selects the correct name. After the correct name is identified, the user can accept the individual name or all occurrences of the name in the document.
 |
Names which are not found can be looked up in the Stottler Henke gazetteer, which includes U.S. and foreign place names, as well as common abbreviations and aliases. If no name is found, the user can mark the name as a place name without recording the coordinates. These can then be hand-edited.
According to T.J. Goan, the Stottler Henke project manager, "This process revolutionizes document-level geoparsing. Following the model for spell checking used by word processing programs, we have integrated a simple and straightforward process to validate the place names and locations. Users can quickly check the place names to verify that all entries meet their requirements and are correctly tagged."
Geoparsing and Microformats
Microformats make information about people, organizations, places, events, opinions, ratings and reviews discoverable by other applications. The power in this approach is that new applications can search tagged documents, discover geospatial content and incorporate this in new mashups. Given the geospatial information contained in the tags, users can automatically generate maps, charts or tables to accompany the text. In addition they can link the content to other information to create totally new content. The applications using the tags may or may not be known to the authors of the documents, providing greater reuse and value to the community.
Dave Dearing, the GeoDoc lead software developer, noted, "This approach is in keeping with the Web philosophy of tagging, then sharing; rather than sharing and then tagging. Most existing geoparsing products follow the latter approach."
Microformats are machine-readable, semantic mark-up formats that are gaining in popularity. They are human-readable and built upon widely adopted standards. Most importantly, the Stottler Henke Associates' geoparsing process embeds Microformats non-destructively in the original text. This allows a user to input a Web page, edit the place names on the page, and output a product that looks like the original page, but contains the semantic information about the mentioned places.
Two of the draft Microformats, the Geo and adr, are relevant for encoding geographic information. The Geo format stores World Geodetic System (WGS) 84 geographic coordinates, while the adr is used to store address information. The adr format is not limited to street addressing, but can address higher level places, such as cities, states and countries which would commonly be found in a gazetteer. Both are suitable for embedding location information in HTML, XHTML, Atom, RSS or arbitrary XML.
Dearing demonstrated the power of geoparsing with Microformats to users by interactively editing a geotagged document using their Web application and then opening a geotagged document in the Firefox browser with the Operator Add-In.
Operator automatically detects Microformats related to contacts, events, locations, tagspaces, bookmarks and resources.
 |
He opened a Web page that showed all the original information, with the addition that place names were now underlined. Coordinates were displayed when he hovered the cursor over the name. The place names were identified as locations in the Operator toolbar. The user could select a location and view it in Google Maps, MapQuest or Yahoo! Maps, or export an individual name or all the place names to the Keyhole Markup Language (KML) for display in a variety of applications.
 |
Dearing observed, "Operator is a tool that discovers and exploits Microformats. Working with Operator is a good way for users to begin to explore the potential for semantic tagging and requires no additional development."
Microformats are not the only format available for geospatial semantic tagging. Other formats, like the Resource Description Framework (RDF) or community-based tagging systems, offer alternatives. However, at this point Microformats are widely used and readily available, with simple tools in place to exploit the information.
Aaron Novstrup, a GeoDoc Web developer at Stottler Henke, observed, "From a programming perspective, Microformats are quick and simple to implement and are easy to exploit. They represent a good first step for developers and users. Our GeoDoc framework is flexible and will easily accommodate other semantic tagging standards as they evolve and we currently offer a Geography Markup Language (GML)-based output as well."
Geoparsing applications will continue to evolve and develop rapidly in the near future, as the ability to extract and tag places improves. There will always be a place for document-level place checking and the use of semantic tagging to support the discovery and exploitation of place names in text.
The Way Ahead
Stottler Henke's GeoDoc application demonstrates two key components of the future of geoparsing: interactive editing and semantic tagging. Military users will not only want to exploit automatically geoparsed documents, they will require a capability to efficiently edit the results to certify that the place names in the document are all geotagged, and geotagged correctly. Just as cartographers review and validate map content prior to publication, geospatial analysts will review and validate geotagged text documents. Place checking, like spell checking, allows users to quickly and easily edit the content of their documents.
GeoDoc produces semantically tagged documents, which contain information that can be discovered and exploited by other applications, which can mashup the data with other Web content. The application currently outputs to a GML format, as well as a Microformat-based output. The Microformat output non-destructively inserts tags in the original document that are recognized by applications such as Operator, a Foxfire add-on. With the recognition of the importance of semantically tagged content, military organizations and government agencies will increasingly incorporate tags with their published content. Users who discover and exploit this information will be able to automatically generate maps, charts and tables related to the text, as well as mash-up the geospatial content with other information.
Resources
Stottler Henke Associates
US Army Engineer Research and Development Center
Microformats
From Our Homepage
Saying Farewell to an Amazing Journey
Communicating with Maps
Is There a GIS Career Ladder?
What does it mean to be geospatially smart? Series
Ways Real Estate and Property Developers Utilize Melissa GeoData for Data-Driven Decisions
Unlocking Value From Daily Satellite Imagery and Insights
Maximizing the Value of Your Address Data with Geo Addressing
How Indoor Mapping Enhances the Security of Smart Buildings
Look Ahead: AI, Location Intelligence and Efficiency
Collaboration Takes on Sea Level Rise & Dynamic Technology Environments
Brownies for Brownfields
Has Everything Been Mapped Already?
How Is Data Literacy Changing in an Artificial Intelligence Landscape
Portfolios for GIS Professionals: More Than Just Maps
How to Create a Distance Matrix in QGIS - A Step-by-Step Guide
7 Ideas for Bringing GIS into the K-12 Classroom
The Geography of Movement