Integration. Fusion. Conflation. All these terms refer
to matching two different data sets together. That's something that's
been done for decades in our industry, so could there possibly be
anything new? Yes!
The new idea came from one of the next generation thinkers in our field, Jason Chen, director of Research and Development at Geosemble Technologies. It was his PhD work under Cyrus Shahabi and Craig Knoblock, co-founders of Geosemble and faculty members at the University of Southern California (USC), that underlies the new capability.
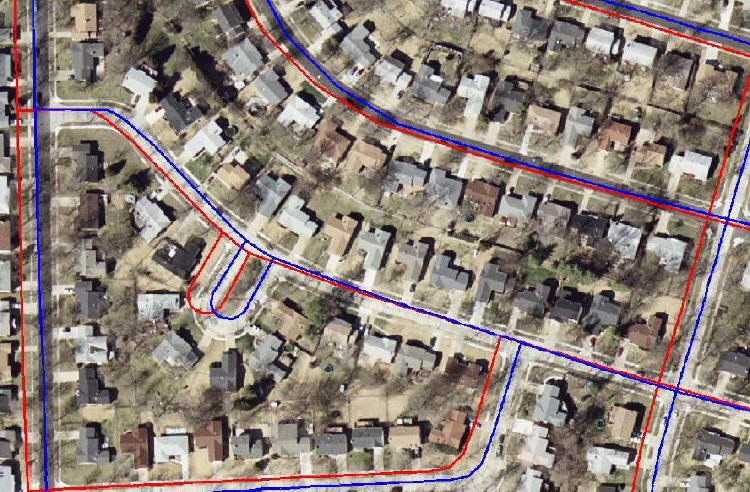
Most readers are familiar with how geospatial software warps or rubbersheets one data set (raster or vector) to another (raster or vector). The first step is finding matching points on the two datasets. That's a time consuming, manual process that depends on the "computer between our ears." The user looks for matching intersections or other standout points and typically "clicks" on each point, first in the source dataset, then in the target dataset. Once the points, a minimum of three or in some programs hundreds or more, are defined, a simple (affine = projection, rotation and scaling) or complex (multivariate) algorithm determines how to mathematically map one dataset to the other.
The Geosemble innovation is in the first part of the process: algorithms fully automate the selection of the matching points. Shahabi explained the three step process for matching vector data to raster.
First, the software uses the vector data to find street intersections. Once the points are found on the vector data, the information is used to look for matches on the image.
Second, the software searches the image for a matching intersection. It uses the coordinates from the vector data to find a starting point for the search, but it's only a "ball park" location. The system uses other information including the number of roads at the intersection (2, 3, 4, 5), the width of the road (if available), and the angle of the intersection to find the best candidate matches for each intersection found.
Third, the software filters out matches that are questionable. How? It finds ones that don't seem to fit the "shift" (the direction and distance change in x and y required to match the vector point) needed for points around it. Those that are "too far off" are dropped as outliers, leaving only source/target pairs with a very high accuracy confidence level.
In a sense, this process isn't so different from how an experienced professional would make the selections manually. Once complete, the same sort of mathematical transformations described above are calculated and applied to fuse the datasets.
Geosemble touts these benefits of its system. "Many users have a shortage of trained analysts to perform this work. With the Geosemble capability, the usable information can be extracted quickly, accurately and automatically, thereby making the data available to decision makers. Further, with the automation of this process, the software is able to process vast amounts of data, allowing users to benefit from extracting more value from imagery sooner than might otherwise be the case, even with trained personnel doing imagery analysis."
Shahabi and Knoblock founded Geosemble in 2004 and licensed the technology from USC in June of 2005. The company began to grow with grants for research from DARPA, the National Science Foundation and USGS and later from the U.S. Air Force, the intelligence community and most recently the Department of Homeland Security.
These days, Geosemble is taking the ideas to a new market, a commercial
one that wants to match up not road intersections, but closed parcel
boundaries, to imagery. It turns out that working with parcels, despite
the more complex geometry, is actually more accurate than fusion based
on road intersections. The rise of real estate websites like Zillow
that offer imagery and further details for home buyers is creating a
new demand for fused geospatial data. And the datasets to be fused are
potentially huge, perhaps including all the major cities of the United
States. For now, Geosemble is providing services for fusion but it is
working with interested clients to productize its solution for those
who want to run it in-house. Shahabi expects that soon the core tools
will be packaged as extensions to GIS and imagery products.
Geosemble came to my attention from a press
release announcing a
contract with the US Air Force Office of Scientific Research (AFOSR).
Shahabi explained that the AFOSR work will develop a solution to fuse
raster maps with imagery. Per the press release, the "technology will
allow a user to view a satellite image for any place in the world,
automatically find and align the maps covering that region, and then
overlay selected layers from the map to better understand the
information shown in an image." The process essentially will vectorize
one layer from the map (the roads, for example) and use the process
described above to match it up with an image. That way, map annotation,
points of interest, etc. are also fused to the image.
If the future of aerial and satellite imagery depends on finding new ways to use it and manage it, Geosemble appears to be in the right place at the right time.
The new idea came from one of the next generation thinkers in our field, Jason Chen, director of Research and Development at Geosemble Technologies. It was his PhD work under Cyrus Shahabi and Craig Knoblock, co-founders of Geosemble and faculty members at the University of Southern California (USC), that underlies the new capability.
Most readers are familiar with how geospatial software warps or rubbersheets one data set (raster or vector) to another (raster or vector). The first step is finding matching points on the two datasets. That's a time consuming, manual process that depends on the "computer between our ears." The user looks for matching intersections or other standout points and typically "clicks" on each point, first in the source dataset, then in the target dataset. Once the points, a minimum of three or in some programs hundreds or more, are defined, a simple (affine = projection, rotation and scaling) or complex (multivariate) algorithm determines how to mathematically map one dataset to the other.
 |
The Geosemble innovation is in the first part of the process: algorithms fully automate the selection of the matching points. Shahabi explained the three step process for matching vector data to raster.
First, the software uses the vector data to find street intersections. Once the points are found on the vector data, the information is used to look for matches on the image.
Second, the software searches the image for a matching intersection. It uses the coordinates from the vector data to find a starting point for the search, but it's only a "ball park" location. The system uses other information including the number of roads at the intersection (2, 3, 4, 5), the width of the road (if available), and the angle of the intersection to find the best candidate matches for each intersection found.
Third, the software filters out matches that are questionable. How? It finds ones that don't seem to fit the "shift" (the direction and distance change in x and y required to match the vector point) needed for points around it. Those that are "too far off" are dropped as outliers, leaving only source/target pairs with a very high accuracy confidence level.
In a sense, this process isn't so different from how an experienced professional would make the selections manually. Once complete, the same sort of mathematical transformations described above are calculated and applied to fuse the datasets.
Geosemble touts these benefits of its system. "Many users have a shortage of trained analysts to perform this work. With the Geosemble capability, the usable information can be extracted quickly, accurately and automatically, thereby making the data available to decision makers. Further, with the automation of this process, the software is able to process vast amounts of data, allowing users to benefit from extracting more value from imagery sooner than might otherwise be the case, even with trained personnel doing imagery analysis."
Shahabi and Knoblock founded Geosemble in 2004 and licensed the technology from USC in June of 2005. The company began to grow with grants for research from DARPA, the National Science Foundation and USGS and later from the U.S. Air Force, the intelligence community and most recently the Department of Homeland Security.
 |
 |
If the future of aerial and satellite imagery depends on finding new ways to use it and manage it, Geosemble appears to be in the right place at the right time.
From Our Homepage
Saying Farewell to an Amazing Journey
Communicating with Maps
Is There a GIS Career Ladder?
What does it mean to be geospatially smart? Series
Ways Real Estate and Property Developers Utilize Melissa GeoData for Data-Driven Decisions
Unlocking Value From Daily Satellite Imagery and Insights
Maximizing the Value of Your Address Data with Geo Addressing
How Indoor Mapping Enhances the Security of Smart Buildings
Look Ahead: AI, Location Intelligence and Efficiency
Collaboration Takes on Sea Level Rise & Dynamic Technology Environments
Brownies for Brownfields
Has Everything Been Mapped Already?
How Is Data Literacy Changing in an Artificial Intelligence Landscape
Portfolios for GIS Professionals: More Than Just Maps
How to Create a Distance Matrix in QGIS - A Step-by-Step Guide
7 Ideas for Bringing GIS into the K-12 Classroom
The Geography of Movement