Ed. note: This article was updated since it was first published. Figure 6 has been changed and the issue regarding block (see first comment) has been addressed.
The human brain has a limited capacity to store and
process large
quantities of information. To handle overwhelming complexities of
detail the mind will often break down large chunks of data into
manageable tracts for processingi. A
prominent topic
in which
information gets segmented is place identification. In geography, areas
are frequently divided into smaller regions. In the United States, the
country is a collection of states and territories comprised of counties
with cities and towns. These regions are further subdivided into
officially recognized designations: ZIP Codes, census tract groups and
census tracks based on numeric designations.
This article will outline a process used for breaking down cities and towns into alternative regions structured on name recognitionii: neighborhoods, districts or other local areas. Based on the demographic data gathered using these techniques - collected from the 250 largest U.S. cities' neighborhoods - evidence will be given to support the potential benefits to quantifying city data based on neighborhood names and their accompanying structures rather than traditionally used U.S. Censusiii regions. The process defines neighborhood boundaries based on commonly recognized characteristics such as widespread reference by community, as well as natural and human demarcations.
Through defined neighborhood datasets and boundaries, the study will attempt to show that locally correlated attributes with recognizable names can provide cohesive information for a given region. The analysis hopes to convince the reader that neighborhoods, with their flexibility to form organically, prove in many cases to be a better solution to collecting demographic data than census measurements, which are often confined to a fixed quantity amalgamation of census tracts, units that are generally restricted to a set population for a given regioniv.
Analysis Overview
The U.S. Censusv designates that a census tract typically ranges between 1,500 - 8,000 people, with a stated ideal size being 4,000 individuals. This uniformity for a tract group forces demographic units to conform to a fixed population rather than a neighborhood demographic that may vary in population (e.g. census tracts for San Francisco, California average 4,000 people, while San Francisco neighborhoods range in population from 250 - 37,000 individuals)vi.
By arbitrarily combining fixed measurements, demographic consistency is greatly diminished, in part because fixed population sizes force exclusion of nearby regions that may share characteristics or restrict inclusion of areas with a different distinct identity. This problem becomes more pervasive as groupings become larger, as seen with ZIP Code divisions where size (roughly 2-5 census block groups)vii boundaries are chiefly determined by the amount of mail that can be delivered from a post office, not by determining an area's socio-economic characteristics.
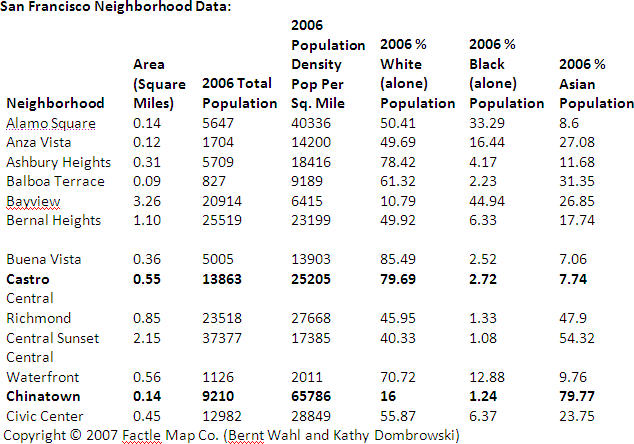
Ethnicity and income also play a roll in defining certain neighborhoods. In most large U.S. cities you will find ethnic communities. These clusters often form the basis of neighborhoods. By definition they will often have members who share a certain amount of continuity in their life style, income and activism. Over time, their activities may inspire similar/like-minded groups to move in, while encouraging others to leave. In San Francisco extreme cases of this can be seen in the density of the Chinese population in "Chinatown" and the gay population found in the Castro. The demographic data below show that neighborhoods come in various sizes with different characteristics.
Neighborhood Definition
A neighborhood is a place built on identity. Physical neighborhoods [generally] form around specific geographic characteristics (Identifying Urban Neighborhoods: An Annotated Biography Thomas F. Broden, Ronn Lirkwood, Susan Roberts, John Roos, Thomas Swartz Council of Planning Librarians Institute for Urban Studies Notre Dame (1980)), deriving boundaries from distinct elements: a hill, a seaside, a central district, or from surrounding roads. These distinctions such as "hills" and "valleys" often define desirability (e.g. a higher elevation with a view probably being more valuable than a reclaimed lowland "mudflat"). Other neighborhoods use functional, political or economic differentiation united by a common culture, age and heritage or through distinctive characteristics such as a gated community, commerce designated area, industrial zone or a "seedy part" of town.
To begin our analysis, we need to create a systematic way to define the physical boundaries of neighborhoods from which data can be quantified. From the beginning we understand that describing neighborhood locations precisely could prove controversial. People have different opinions on what constitutes a neighborhoodviii. For this reason we consulted experts in GIS mapping, city planning and real estate sales, as well as ordinary citizens, to supply input on building our neighborhood map designations. While achieving an absolute consensus for defining neighborhoods would be unlikely, our goal is to provide a comprehensive system that generates neighborhood data that many users - especially individuals conducting online queries or doing neighborhood research - would find helpful in seeking local information. After careful study, a systematic multi-step process was created that tries to quantify what defines a physical neighborhood structure (see Process List below). We also realized that if it could be done successfully the social and economic gains could be substantialix for users.
In our observations, we notice the historical significance of neighborhoods. In many regions, neighborhood names are often passed on through an oral tradition where local inhabitants make reference to a given area, often based on an original name given to a subdivision by a developer (in Berkeley, California districts like the Claremont, Elmwood or by a region's functional use). Then over time neighborhood boundaries are further refined by city professionals that quantify a region's borders by setting demarcations based on zoning, district boundaries or through road construction. Below is an outline of some elements of our 20-step process used to define neighborhoods. Different nations will have variations on how data are collected.
Process List for collecting neighborhood data:
Methodology for Recognizing and Defining Physical Neighborhood Boundariesx
Descriptive Boundaries Method: Identifies neighborhoods using existing maps and natural boundaries with a combination of data from city planning offices, chambers of commerce, local real estate firms and other sourcesxi. By comparing neighborhood descriptions with local maps, you can get an understanding of how neighborhoods are perceived by different members of a local community.
Areas where a strong consensus exists - usually confirmed by several independent sources - usually get incorporated into maps first. Old established cities (e.g. Boston, New York) generally have clear distinct neighborhood designations. It appears that with age, a city's established neighborhood identity solidifies over timexii.
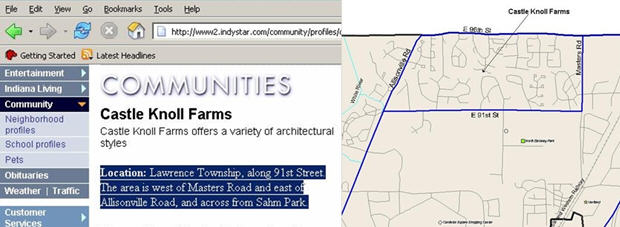
When conflicting, ambiguous or non-existing boundaries occur, local organizations within those areas are contacted in hopes of resolving unidentified neighborhood areas. Based on information provided, a best guess estimate is chosen or the area is left blank. The neighborhoods are then traced out by locating major streets and other boundaries. Maps generated with this method often are quite comprehensive. As a neighborhood changes or new information becomes available, modifications can be made.
The above image shows an Indianapolis neighborhood map generated from
descriptions of an online newspaper website.
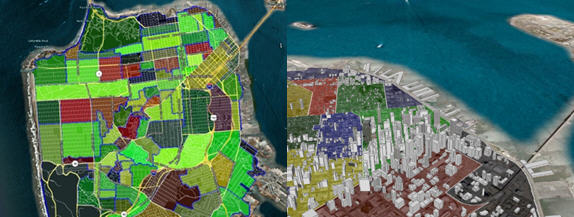
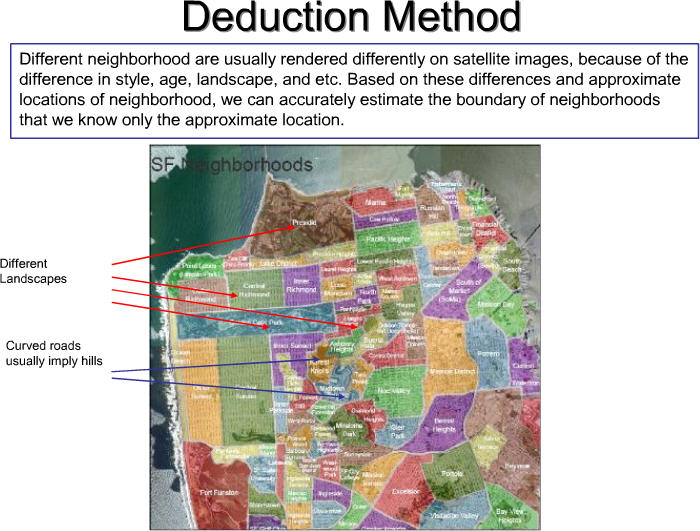
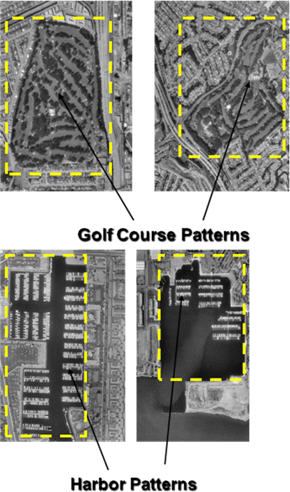
Deduction Method: This method uses maps and satellite images to estimate neighborhood demarcations. Different neighborhoods usually render recognizable patterns (e.g. squiggly patterns often represent hills where the roads are not straight) on satellite images. These patterns often consist of commonalities that neighborhoods share: style, age, landscape or other factors. Based on these differences coupled with a neighborhood's approximate location, an accurate boundary estimate can often be made. Factors such as road accessibility and terrain can play an integral part of a neighborhood's formation. A technique used to measure the Deduction Method's accuracy is to map out a city's neighborhoods with this method - where neighborhood boundaries are known - and compare the results of known neighborhoods to hypothesized samples.
Today different land uses are mostly traced out by humans. In the future OIR (Optical Image Recognition) systems will be able to identify structures, extract commonalities and cluster data based on image patterns. For example, picture data will recognize neighborhood clusters based on relative housing styles or grouped lot sizes. There may even come a time when demographic inferences are made based on the car parked in the driveway.
The above image shows an accurate neighborhood map of San Francisco
based on visually identified neighborhoods on a satellite image.
Other images will also give inference to neighborhood qualities; parks,
stadiums, golf courses and harbors will be identified and classified by
comparing them to stock items in a database with known characteristics.
Structural information gleaned can then provide an insight into
neighborhood characteristics along with already know, compiled
information to give a demographic preference livability score. In our
collection we have already collected locations for more than 1.2
million U.S. places of interest that can be factored into a quality of
life matrix. As our understanding of neighborhood formation and
characteristics increases, we speculate that algorithms will be created
that will be able to discern different neighborhood uniqueness, similar
to the way pattern recognition software can differentiate different
types of buildings, as well as other geographic structures. This
neighborhood demographic analysis will be able to aid a user in
selecting a neighborhood that most closely resembles a user's desired
characteristics.
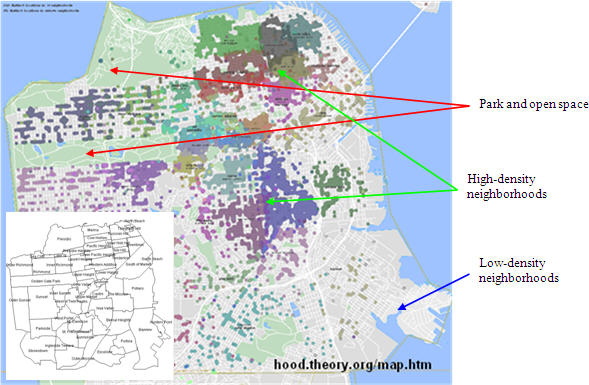
Scatter Plot Method: This method aggregates a collection of data points to assemble a map from which neighborhood boundaries can be constructed. This method is useful for allowing many users to contribute to the construction of neighborhood boundaries, as well as being able to monitor changes to neighborhood patterns in adjacent areas. For example, real estate agent listings on Craigslist, Realtor.com or Google Base could integrate the scatter plot method to help users to define neighborhood locations. Location aware mobile devices (GPS) will conceivable play a significant roll in creating boundaries as location coordinates become associated with "tagged" descriptive information.
The scatter plot data show that clustering exists between San Francisco neighborhoodsxiii. This method of data collection holds great promise for mapping neighborhoods. As people gain access to GPS-enabled cameras, a flood of corresponding location data should ensue, enabling an ever increasing amount of neighborhood boundary data for users. These data should also provide neighborhood name recognition statistics for given areas.
We produced boundary data at both U.S. government issued TIGER level
(red) and the more exacting 1.5 - 3.0 meter quality level (green).
TIGER data were needed to aggregate U.S. Census demographic data for
neighborhoods and the higher quality data were needed for precision
matching of streets.
Acknowledgments
• School of Information
• Richard Dorall, Factle Maps & University of Malaya
• Cheng Ming Yu, Multimedia University
• Michael Cho, UC Berkeley iMap co-author
• MOT Business Team
• UC Berkeley Interns and Kathy Dombrowski
• University of Malaya GIS Team
• UC Berkeley SSIP
• Shawn Newsam, UC Merced - Image Technology
• Information Access Seminar Group
• Center of Entrepreneurship and Technology
• Google, Yahoo & Microsoft (GYM)
Footnotes:
iAtkinson, R.C. & Shiffrin, R.M. (1968) Human memory: A proposed system and its control processes. In K.W. Spence and J.T. Spence (Eds.), The psychology of learning and motivation, vol. 8. London: Academic Press.
iiBased on informal sampling of over 25 people who reside in the San Francisco Bay Area to see how many could name their neighborhood vs. census block. A majority could name their neighborhood or a nearby neighborhood; most residents did not know what constituted a census block and only one person responded with a census block answer. It was not confirmed if it actually was a correct answer. In the future a more formal study should be done on the number of people who can accurately define which neighborhood they reside in.
iiiMore information about census blocks and block groups are available in the glossary at the U.S. Census website: http://www.census.gov/
ivCensus tracts delineated by local committees in accordance with census bureau guidelines used in collecting census data. Census tracts are made up of block groups. Their boundaries generally follow visible features, though under some circumstances their boundaries may follow governmental unit boundaries or other features. http://www.tlc.state.tx.us/redist/glossary.htm
vU.S. Census: http://www.nctcog.org/ris/census/
viBased on Kathleen Dombrowski and Bernt Wahl raw neighborhood data, of 150 U.S. cities with 7000 neighborhoods (size, population, density, and demographic statistics) provided by Factle Map Co. based on 2006 MapInfo data.
viiMore information about census blocks and block groups are available in the glossary at the U.S. Census website: http://www.census.gov/
viiiShaping Neighborhoods: A Guide for Health, Sustainability and Vitality, Hugh Barton, Marcus Grant and Richard Guise (2003) Spon Press, London
ixBased on an internal HomeGain study, the firm believes adding neighborhood search terms will boost SEO search revenues (2nd largest online real estate firm) by 20% or millions of dollars (Bernt Wahl, consultant (2005)). Based on the firm's internal data analysis it is estimated that about 20-30% of home buyers would prefer to search for homes that include neighborhood regions. Internal traffic records have shown a strong correlation (internal HomeGain traffic records (2006)). Based on similar correlation study if Google could capture 5% of its $500 million local search revenue from targeted neighborhood results, this would increase revenues by $25 million.
xPortions of descriptions and uses are based on prior collaborations, Malaysian Team - (2001-2008), HomeGain Team (2005-2006), MOT Leading Edge Completion Team (2006)
xiReadings on reputation and sourcing [add comments]
xiiAn exception would be "neighborhood name" gentrification where an established area with a name that is less desirable would try to assimilate an adjacent name or create a new identity (e.g. Temescal becoming Upper Rockridge in Oakland, California).
xiiiMatt Chisholm and Ross Cohen, The Neighborhood Project www.theory.org
 |
This article will outline a process used for breaking down cities and towns into alternative regions structured on name recognitionii: neighborhoods, districts or other local areas. Based on the demographic data gathered using these techniques - collected from the 250 largest U.S. cities' neighborhoods - evidence will be given to support the potential benefits to quantifying city data based on neighborhood names and their accompanying structures rather than traditionally used U.S. Censusiii regions. The process defines neighborhood boundaries based on commonly recognized characteristics such as widespread reference by community, as well as natural and human demarcations.
 |
Through defined neighborhood datasets and boundaries, the study will attempt to show that locally correlated attributes with recognizable names can provide cohesive information for a given region. The analysis hopes to convince the reader that neighborhoods, with their flexibility to form organically, prove in many cases to be a better solution to collecting demographic data than census measurements, which are often confined to a fixed quantity amalgamation of census tracts, units that are generally restricted to a set population for a given regioniv.
Analysis Overview
The U.S. Censusv designates that a census tract typically ranges between 1,500 - 8,000 people, with a stated ideal size being 4,000 individuals. This uniformity for a tract group forces demographic units to conform to a fixed population rather than a neighborhood demographic that may vary in population (e.g. census tracts for San Francisco, California average 4,000 people, while San Francisco neighborhoods range in population from 250 - 37,000 individuals)vi.
By arbitrarily combining fixed measurements, demographic consistency is greatly diminished, in part because fixed population sizes force exclusion of nearby regions that may share characteristics or restrict inclusion of areas with a different distinct identity. This problem becomes more pervasive as groupings become larger, as seen with ZIP Code divisions where size (roughly 2-5 census block groups)vii boundaries are chiefly determined by the amount of mail that can be delivered from a post office, not by determining an area's socio-economic characteristics.
Ethnicity and income also play a roll in defining certain neighborhoods. In most large U.S. cities you will find ethnic communities. These clusters often form the basis of neighborhoods. By definition they will often have members who share a certain amount of continuity in their life style, income and activism. Over time, their activities may inspire similar/like-minded groups to move in, while encouraging others to leave. In San Francisco extreme cases of this can be seen in the density of the Chinese population in "Chinatown" and the gay population found in the Castro. The demographic data below show that neighborhoods come in various sizes with different characteristics.
 |
 |
Neighborhood Definition
A neighborhood is a place built on identity. Physical neighborhoods [generally] form around specific geographic characteristics (Identifying Urban Neighborhoods: An Annotated Biography Thomas F. Broden, Ronn Lirkwood, Susan Roberts, John Roos, Thomas Swartz Council of Planning Librarians Institute for Urban Studies Notre Dame (1980)), deriving boundaries from distinct elements: a hill, a seaside, a central district, or from surrounding roads. These distinctions such as "hills" and "valleys" often define desirability (e.g. a higher elevation with a view probably being more valuable than a reclaimed lowland "mudflat"). Other neighborhoods use functional, political or economic differentiation united by a common culture, age and heritage or through distinctive characteristics such as a gated community, commerce designated area, industrial zone or a "seedy part" of town.
To begin our analysis, we need to create a systematic way to define the physical boundaries of neighborhoods from which data can be quantified. From the beginning we understand that describing neighborhood locations precisely could prove controversial. People have different opinions on what constitutes a neighborhoodviii. For this reason we consulted experts in GIS mapping, city planning and real estate sales, as well as ordinary citizens, to supply input on building our neighborhood map designations. While achieving an absolute consensus for defining neighborhoods would be unlikely, our goal is to provide a comprehensive system that generates neighborhood data that many users - especially individuals conducting online queries or doing neighborhood research - would find helpful in seeking local information. After careful study, a systematic multi-step process was created that tries to quantify what defines a physical neighborhood structure (see Process List below). We also realized that if it could be done successfully the social and economic gains could be substantialix for users.
In our observations, we notice the historical significance of neighborhoods. In many regions, neighborhood names are often passed on through an oral tradition where local inhabitants make reference to a given area, often based on an original name given to a subdivision by a developer (in Berkeley, California districts like the Claremont, Elmwood or by a region's functional use). Then over time neighborhood boundaries are further refined by city professionals that quantify a region's borders by setting demarcations based on zoning, district boundaries or through road construction. Below is an outline of some elements of our 20-step process used to define neighborhoods. Different nations will have variations on how data are collected.
Process List for collecting neighborhood data:
- Go to official city sites to see if mapping data are publicly available. Generally follow given city neighborhood boundary definitions closely where available so that data follow the consensus of the community.
- View maps that can be used as map backgrounds to raster images; try to have at lease two sources of data to make comparisons.
- Visit sites with local information: official city sites, local chamber of commerce sites, etc.
- Call local city chamber of commerce, city planning or regional real estate agents to ask for descriptions (identify yourself as part of a research group, where data gathered serve the community).
- Visit or send out emails to local real estate agents or local residents to contribute information online.
Methodology for Recognizing and Defining Physical Neighborhood Boundariesx
Descriptive Boundaries Method: Identifies neighborhoods using existing maps and natural boundaries with a combination of data from city planning offices, chambers of commerce, local real estate firms and other sourcesxi. By comparing neighborhood descriptions with local maps, you can get an understanding of how neighborhoods are perceived by different members of a local community.
Areas where a strong consensus exists - usually confirmed by several independent sources - usually get incorporated into maps first. Old established cities (e.g. Boston, New York) generally have clear distinct neighborhood designations. It appears that with age, a city's established neighborhood identity solidifies over timexii.
When conflicting, ambiguous or non-existing boundaries occur, local organizations within those areas are contacted in hopes of resolving unidentified neighborhood areas. Based on information provided, a best guess estimate is chosen or the area is left blank. The neighborhoods are then traced out by locating major streets and other boundaries. Maps generated with this method often are quite comprehensive. As a neighborhood changes or new information becomes available, modifications can be made.
 |
Deduction Method: This method uses maps and satellite images to estimate neighborhood demarcations. Different neighborhoods usually render recognizable patterns (e.g. squiggly patterns often represent hills where the roads are not straight) on satellite images. These patterns often consist of commonalities that neighborhoods share: style, age, landscape or other factors. Based on these differences coupled with a neighborhood's approximate location, an accurate boundary estimate can often be made. Factors such as road accessibility and terrain can play an integral part of a neighborhood's formation. A technique used to measure the Deduction Method's accuracy is to map out a city's neighborhoods with this method - where neighborhood boundaries are known - and compare the results of known neighborhoods to hypothesized samples.
Today different land uses are mostly traced out by humans. In the future OIR (Optical Image Recognition) systems will be able to identify structures, extract commonalities and cluster data based on image patterns. For example, picture data will recognize neighborhood clusters based on relative housing styles or grouped lot sizes. There may even come a time when demographic inferences are made based on the car parked in the driveway.
 |
 |
Scatter Plot Method: This method aggregates a collection of data points to assemble a map from which neighborhood boundaries can be constructed. This method is useful for allowing many users to contribute to the construction of neighborhood boundaries, as well as being able to monitor changes to neighborhood patterns in adjacent areas. For example, real estate agent listings on Craigslist, Realtor.com or Google Base could integrate the scatter plot method to help users to define neighborhood locations. Location aware mobile devices (GPS) will conceivable play a significant roll in creating boundaries as location coordinates become associated with "tagged" descriptive information.
The scatter plot data show that clustering exists between San Francisco neighborhoodsxiii. This method of data collection holds great promise for mapping neighborhoods. As people gain access to GPS-enabled cameras, a flood of corresponding location data should ensue, enabling an ever increasing amount of neighborhood boundary data for users. These data should also provide neighborhood name recognition statistics for given areas.
 |
 |
Acknowledgments
• School of Information
• Richard Dorall, Factle Maps & University of Malaya
• Cheng Ming Yu, Multimedia University
• Michael Cho, UC Berkeley iMap co-author
• MOT Business Team
• UC Berkeley Interns and Kathy Dombrowski
• University of Malaya GIS Team
• UC Berkeley SSIP
• Shawn Newsam, UC Merced - Image Technology
• Information Access Seminar Group
• Center of Entrepreneurship and Technology
• Google, Yahoo & Microsoft (GYM)
Footnotes:
iAtkinson, R.C. & Shiffrin, R.M. (1968) Human memory: A proposed system and its control processes. In K.W. Spence and J.T. Spence (Eds.), The psychology of learning and motivation, vol. 8. London: Academic Press.
iiBased on informal sampling of over 25 people who reside in the San Francisco Bay Area to see how many could name their neighborhood vs. census block. A majority could name their neighborhood or a nearby neighborhood; most residents did not know what constituted a census block and only one person responded with a census block answer. It was not confirmed if it actually was a correct answer. In the future a more formal study should be done on the number of people who can accurately define which neighborhood they reside in.
iiiMore information about census blocks and block groups are available in the glossary at the U.S. Census website: http://www.census.gov/
ivCensus tracts delineated by local committees in accordance with census bureau guidelines used in collecting census data. Census tracts are made up of block groups. Their boundaries generally follow visible features, though under some circumstances their boundaries may follow governmental unit boundaries or other features. http://www.tlc.state.tx.us/redist/glossary.htm
vU.S. Census: http://www.nctcog.org/ris/census/
viBased on Kathleen Dombrowski and Bernt Wahl raw neighborhood data, of 150 U.S. cities with 7000 neighborhoods (size, population, density, and demographic statistics) provided by Factle Map Co. based on 2006 MapInfo data.
viiMore information about census blocks and block groups are available in the glossary at the U.S. Census website: http://www.census.gov/
viiiShaping Neighborhoods: A Guide for Health, Sustainability and Vitality, Hugh Barton, Marcus Grant and Richard Guise (2003) Spon Press, London
ixBased on an internal HomeGain study, the firm believes adding neighborhood search terms will boost SEO search revenues (2nd largest online real estate firm) by 20% or millions of dollars (Bernt Wahl, consultant (2005)). Based on the firm's internal data analysis it is estimated that about 20-30% of home buyers would prefer to search for homes that include neighborhood regions. Internal traffic records have shown a strong correlation (internal HomeGain traffic records (2006)). Based on similar correlation study if Google could capture 5% of its $500 million local search revenue from targeted neighborhood results, this would increase revenues by $25 million.
xPortions of descriptions and uses are based on prior collaborations, Malaysian Team - (2001-2008), HomeGain Team (2005-2006), MOT Leading Edge Completion Team (2006)
xiReadings on reputation and sourcing [add comments]
xiiAn exception would be "neighborhood name" gentrification where an established area with a name that is less desirable would try to assimilate an adjacent name or create a new identity (e.g. Temescal becoming Upper Rockridge in Oakland, California).
xiiiMatt Chisholm and Ross Cohen, The Neighborhood Project www.theory.org
From Our Homepage
Saying Farewell to an Amazing Journey
Communicating with Maps
Is There a GIS Career Ladder?
What does it mean to be geospatially smart? Series
Ways Real Estate and Property Developers Utilize Melissa GeoData for Data-Driven Decisions
Unlocking Value From Daily Satellite Imagery and Insights
Maximizing the Value of Your Address Data with Geo Addressing
How Indoor Mapping Enhances the Security of Smart Buildings
Look Ahead: AI, Location Intelligence and Efficiency
Collaboration Takes on Sea Level Rise & Dynamic Technology Environments
Brownies for Brownfields
Has Everything Been Mapped Already?
How Is Data Literacy Changing in an Artificial Intelligence Landscape
Portfolios for GIS Professionals: More Than Just Maps
How to Create a Distance Matrix in QGIS - A Step-by-Step Guide
7 Ideas for Bringing GIS into the K-12 Classroom
The Geography of Movement