For the geographic and location industries, the question is: does open source software work in practice? To offer some possible answers, we're going to provide a practical case study of software development for the geographic and location industries using open source products and operating systems. We'll describe our experiences and provide some commentary on where other companies could benefit from the introduction of open source into their services or products.
Window Pains
So what prompted us to start using, let alone developing, open source
software? In 1995 we needed a web site [1] to publish our Windows
software, an Internet based, three-dimensional map viewer, and made the
simple decision to go with the cheapest web account we could find.
Web accounts based on open source operating systems such as Linux [2] and
BSD [3] were half the price of Windows accounts, so we started on BSD in
complete ignorance, and as we needed to extend our web site's functionality,
were forced to extend our knowledge of the open source ecosystem.
Over time our Windows client development started to run into problems. Our product was ambitious even by geographic software standards, and its development time frame was too straining for a small company. What seemed like a constantly changing operating system environment under Microsoft forced constant changes to our software that started to wear on our patience. On the other hand, our Web site development was easy and convenient. Once over the initial open source learning curve, we realized that any software written to the Unix platform would, to all intents and purposes, last forever. While Windows would crash hourly during our C and assembly programming, our server accounts on BSD, and later Linux, never crashed. It wasn't long before we started asking ourselves whether we should develop on some form of open operating system also, and installed Linux on one of our desktops. Eventually it came time to formulate a new business plan, and we gravitated naturally away from our inconveniences with Windows and toward open source operating systems and software.
Development Goals
Our new plan was to develop a Location Search for the Web. The
software would be open source, the operating system would be open source,
and the tools would be open source. We finally felt secure that whatever
time we invested in it would not go to waste due to some sudden operating
system change. Any competitors we would attract would be forced to
compete on their merits, in the open environment of the Web, and as a bonus
we would no longer have to write "what ifs" about Microsoft moving into
our application space in our business plans.
The business plan was to make money from "Location Advertising" [4], which we predicted would eventually be more valuable than ordinary advertising, because of its improved 'targeting', as advertisers call it. We charted the business weakness of banner advertising, and the growing strength of "keyword" text advertising, and adapted our Location Advertising plans accordingly. Open source software was a perfect fit for us because our business model would be strengthened if we gave the software away for free, and it would provide a powerful competitive edge in future.
"Mobilemaps" [1], our Location Search, would allow people to find information
on Web pages that were geographically identifiable as local to them.
We needed to "spider" the Web, crawling from one Web site to another, indexing
the information, and then "geo-code", or geographically locate, each Web
site. We needed to provide a map of the user's area, and plot all
the Web sites on the map, as well as list their titles and descriptions
like a regular search engine.
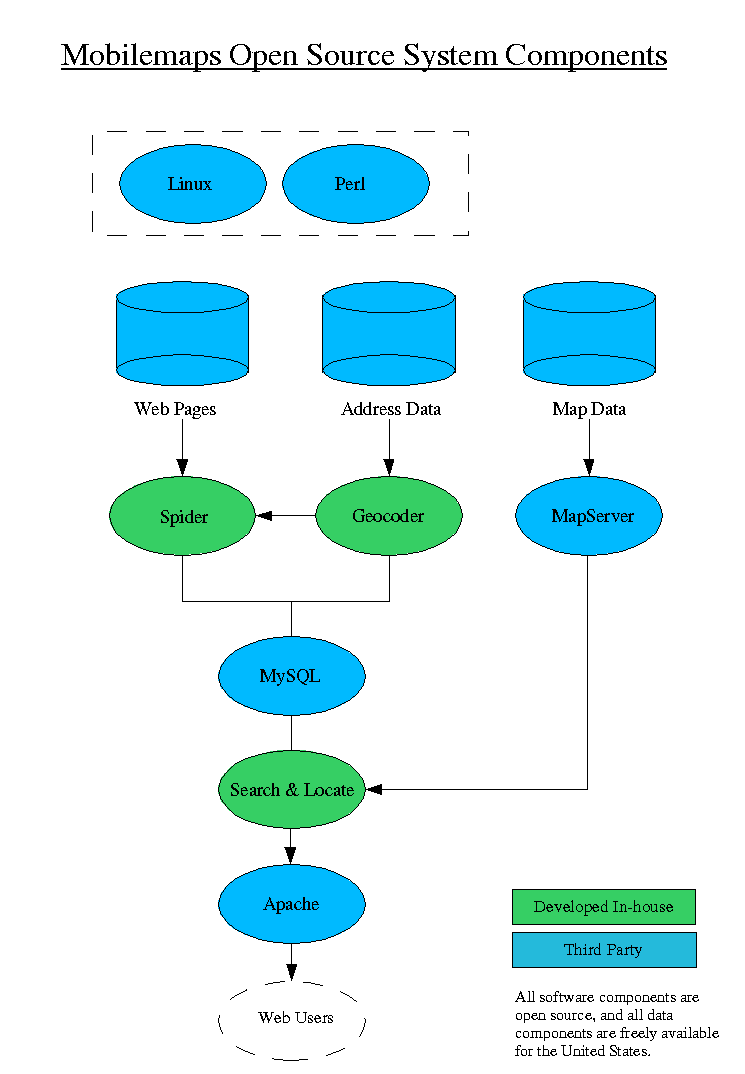
(Click on graphic for larger image)
Choosing Open Source Tools
Our operating system development platform would be Linux, which we
already knew to be considerably more stable than Windows. However,
because of the open nature of the software we would use, our product would
run seamlessly on Windows, and other Unix versions also. This cross
platform compatibility would provide us with an edge over "Windows only"
competing products.
For our Web server it was the easy choice of Apache [5], the world's leading Web server, with more share of the market than all other Web servers combined, including Microsoft's IIS. It has been our experience that text based configuration files for server products such as Apache (which we would recommend for Windows users also) are much more convenient than complicated menu systems, such as those used in IIS. Before making a series of changes you can keep a copy of your old configuration, so if you make a mistake you can revert back to it in a moment. Installing new servers takes no time at all; simply upload an old text file.
Our language of choice was Perl [6], and where necessary we were prepared to optimize using C. While Java has been gaining a lot of attention, Perl has the same or better cross-platform capabilities as Java, and is truly open source, providing no concerns about its future. Perl allows C programmers to get up to speed in a short space of time, offers excellent productivity for experienced programmers, and has an active development community which contributes open source libraries to a common Web repository called CPAN [7]. We selected open source CVS [8] for version control, because it is popular and supports graphical interfaces as well as the command line. It has a reputation for stability, but its functionality is sometimes considered limited compared to some professional Version Control systems, such as Bitkeeper [9] which has been selected by the Linux Kernel developers.
We favor an iterative development methodology, because while developing a radically new product, it is difficult to predict the problems ahead of time, and better to find them quickly during prototyping. We decided to build a rapid search engine prototype using the open source MySQL database [10], with the intention of replacing it with our own code later. We were so impressed with MySQL's performance and stability, however, that we've kept it as an integral part of our engine since. It has helped minimize the quantity of "low-level" C code in our product, and enabled the majority to be "higher-level" Perl, which is faster to develop with.
The latest release of MySQL, version 4.1, includes Geographic database capabilities, which we imagine will see heavy use in a wide range of Geographic and Location based services and products (MySQL offer a closed source license also) in future, but these capabilities were not available during our development. An older open source database, called PostgreSQL [11], has had geographic capabilities for some time, but we were unfamiliar with PostgreSQL and were looking more for performance and convenience than serious functionality (a PostgreSQL user might tell you this is unwarranted stereotyping).
Solving the Problems
While a built-in database geographic capability was a tempting prospect,
we eventually came to realize our Location Search would require a unique
geographic and text algorithm to be truly scalable.
Traditional search engine's, like Google [12], are designed to have an approximately constant look-up time irrespective of their database size, but earlier geographic search engines such as Northern Light's [13] appeared to have a weakness here. To achieve scalability Google must perform most of their sorting of results ahead of the search itself, which can be accomplished by "relevance scoring" words in Web pages and presorting those scores. The question we faced was how to do this for a geographic search which involved proximity? Proximity is constantly changing depending on the location of the searcher, and if we needed to calculate it for every result at every search, our engine would not scale at all. Initially in our prototype we did what other database vendors have done, and limited our results to a defined area, but as the size of our database grew, the area we could search had to keep shrinking to maintain our speed.
Following further research, we realized we would need to use what is called a "space filling curve" or "Peano code", named after the 19th century mathematician who invented them. This curve allows presorting of proximity by forming one continual index that runs through space in a zig-zag pattern. The problem was that the curves proved inaccurate by themselves under certain conditions. An elegant solution was to overlay two space curves on each other, but slightly offset them, and use the best results from either. Currently we combine proximity with a traditional word relevance score in our sort order, so that both closer and more relevant results are found. In this way we succeeded in creating a Location Search engine that is as scalable as a traditional search engine.
Mapping Solutions
Initially our prototype was a pure Location Search, but we wanted to
visually map the search results to provide users with a picture of where
the results were. We prototyped this on our old three-dimensional
map technology, but needed a regular two-dimensional map-server for general
use. Fortunately our need was met by the timely discovery of the
open source MapServer [14] product developed in Minnesota.
While MapServer provides a functional street-level map server, and we can recommend it, the big expense in providing maps over the Internet is usually the data rather than the map-server. North America seems to be alone in adopting the policy that government data funded by the tax-payer should be made available for free to the tax-payer. In European countries, for example, this data is sold for substantial ongoing costs by Governments, which effectively cripples start-up geographic software companies in these territories. In order to adequately demonstrate, and effectively develop our system, we needed to use free TIGER data [15] from the United States Census Bureau.We decided to showcase our technology with Californian Web pages, but we could have picked any other American geography. An additional mention goes to the venerable open source GRASS GIS package [16], that proved useful while manipulating some of our Shape file data.
Harvesting Web Pages
We would have welcomed an open source Web spider, but could not find
one, although we have heard of others becoming available more recently
such as Grub [17]. The Perl LWP libraries provided us with a considerable
head start in developing our own, and we made use of Perl's TK window libraries
to add a simple, cross platform graphical user interface. Currently
different Web sites, or "Portals", using a copy of our Mobilemaps software
must spider independently of each other, with some overlapping effort.
To improve this we are designing distributed spider functionality that
allows different Portals to combine their results, and collaboratively
spider the Web, each becoming an authority on Web pages in their own local
area. Unlike the Looksmart design, there will be no central server,
and the spidered data will be openly available for anyone to use.
Determining Locations
A key component of our Location Search is its "geo-coding" capability,
which could be used as a stand-alone open source tool. We needed
to identify street addresses that were published on Web pages, and then
convert those addresses into geographically coded locations, in degrees
of latitude and longitude. In both the United States and the United
Kingdom at least, there are recognizable zipcode, or postcode patterns
that an autonomous Web spider can find. In the United States there
are also certain patterns to addresses that help to exactly identify what
part of the seemingly random text on a Web page is an address. Once
an address is extracted from an American Web page it can be matched against
the TIGER Census database to identify its location. When a United
Kingdom address is found it can either be cheaply matched against a post-code
database, or matched against a more expensive complete list of geographically
positioned addresses. The powerful "regular expression" text matching
capabilities of the Perl language were very helpful in this respect, and
we used MySQL to store the address databases to match against.
User convenience has marked the popularity of search engines that offer a single search box, so we developed "Sox", a "Single search box", to provide a single input box for Location Searches, and enable a user to type "los angeles wedding photography" and have it do what they expect. This is one of the rare areas of our code that needed the speed of the C language.
Business Models and Results
Open source software typically favors service oriented business models,
although MySQL is a notable example that successfully combines an open
source license with an alternative commercial license. IBM is a typical
example of a company that profits from open source in its consulting services
arm, where Linux provides them with superior profit margins. Mobilemaps
is based on an advertising service model that offers a free sign-up to
its distributed Location Advertising network in exchange for a small percentage
commission on advertising "clicks". While it is of course possible
for companies deploying Mobilemaps software to use whatever advertising
they wish, Mobilemaps offers the immediate convenience of not having to
write a Location Advertising system, and is ultimately likely to offer
better income to Portals due to economies of scale. Before embarking
on an open source project with commercial backing, we recommend finding
a suitable business model that will add value to the entire community who
might use the software, and not just the original investor.
Mobilemaps has successfully released its software after approximately
three man-years of development. It's Location Advertising network
is in the process of deployment, and time will tell whether its open source
business model is competitive. Open source software is an evolutionary
creature, and there is no knowing what uses may be made of our software
in future by the development community. For example we see both its
search and advertising translating easily from the wired Web to the wireless
Location services industry. The great strength of open source development
is the ability to make use of others' contributions, as witnessed by the
numerous open source software packages that helped build our system.
We see this as the most practical network development model, and are confident
that future advances in open source Location Search can now take days or
months rather than years.
References:
[1] Mobilemaps
http://www.mobilemaps.com
[2] Linux
Redhat - http://www.redhat.com
SUSE - http://www.suse.com
Debian - http://www.debian.org
[3] BSD
Open BSD - http://www.openbsd.org
Free BSD - http://www.freebsd.org
Net BSD - http://www.netbsd.org
[4] Abrahamson & Abrahamson, "The Geographic Internet: Open for
Business", Directions Magazine, 2002-12-29, provides further information
about this business model.
http://www.directionsmag.com/article.php?article_id=281
[5] Apache
http://www.apache.org
[6] Perl
http://www.perl.com
[7] CPAN
http://www.cpan.org
[8] CVS
http://www.cvshome.org
[9] Bitkeeper (not open source, but freely available to open source
projects)
http://www.bitkeeper.com
[10] MySQL
http://www.mysql.com
[11] PostgreSQL
http://www.postgresql.org
[12] Google
http://www.google.com
[13] Northern Light (Geographic search also developed by Vicinity, which
is now part of Microsoft)
http://www.northernlight.com
[14] MapServer
http://mapserver.gis.umn.edu
[15] TIGER data, United States Census Bureau
http://www.census.gov/geo/www/tiger/
[16] GRASS GIS
http://grass.baylor.edu/general.html
[17] Grub, an open source distributed spider bought by Looksmart
http://www.grub.org/
Further general information on open source software:
Open Source Initiative (OSI)
http://www.opensource.org/
Free Software Foundation (FSF)
http://www.gnu.org/
Authors:
==============================
Philip Abrahamson
email: philip@mobilemaps.com
url: http://www.mobilemaps.com
Peter Abrahamson
email: peter@mobilemaps.com
url: http://www.mobilemaps.com
==============================