316 Occidental Ave. S.
Suite 410
Seattle, WA 98104-3859
Tel: 206.443.6836
Toll free: 800.750.8830
Fax: 206.269.0694
www.ql2.com
(Ed note: Some very sophisticated tools are used in the process of collecting data, turning it into information, then into knowledge and finally into understanding. WebQL is one of those tools; it can automate and expand the process of data collection and transformation. If you still think that performing a radius or buffer search in your desktop mapping program is a cool way to retrieve information, you really need to read further.)
 |
WebQL is designed to locate data from publicly available sources, but does not traverse firewalls or seek unauthorized access to information that is located or linked within a public website.
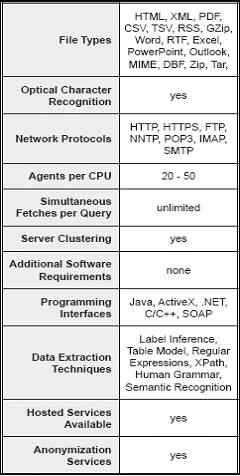
Unlike Google, Ask or Yahoo, WebQL can extract information from free form text, tables, PDF files, hyperlinks, all kinds of file types, and it can even extract text from within graphic files such as .jpg, .tif and .gif. Because of the versatility in creating agents, the information retrieved can be geographic in nature. The agents can be configured to fill out the typical forms needed to get to desired information, which are found on many websites. Multiple agents can run at the same time, too. There is an anonymous option that does the search through a third party, leaving no trace back to the source and no “footprints in the sand” on the targeted websites.
The product requires a fairly high skill level in writing SQL statements or the other programming interfaces in order to make it work. But there is a robust set of tools to aid in data extraction. In addition, if you need just a few specific searches, the company provides the service of creating agents.
Examples of file types and data sources from which WebQL can extract data are listed below (this list is from the company’s literature).
- PDF files
- Image files
- HTML
- Databases
- RSS feeds
- PowerPoint files
- Word documents
- Zip files
- Data mining for customer and competitor information to support CRM applications.
- Web mining for business activity monitoring (BAM), business process management (BPM) and executive dashboard applications.
- Gathering large amounts of unstructured text for indexing, data mining and “fingerprinting” by advanced text analysis tools.
- Aggregating content for enterprise information portals.
- Harvesting online competitive pricing data for revenue management and price optimization systems.
- Collecting and indexing data for enterprise search and metadata management.
- Watching the competition, pricing news, promotions, patents, hiring trends, SEC filings, licenses, expansion plans, etc.
- Automating research, locating, extracting and organizing information from multiple scientific information portals.
- Performing primary research, monitoring public opinion from cyber forums, blogs and RSS feeds about products and competitors.
- Internet monitoring of partners, resellers and the gray market for resale authorization price accuracy, logo usage, logo positioning, links to and from partner sites, intellectual property violations, etc.
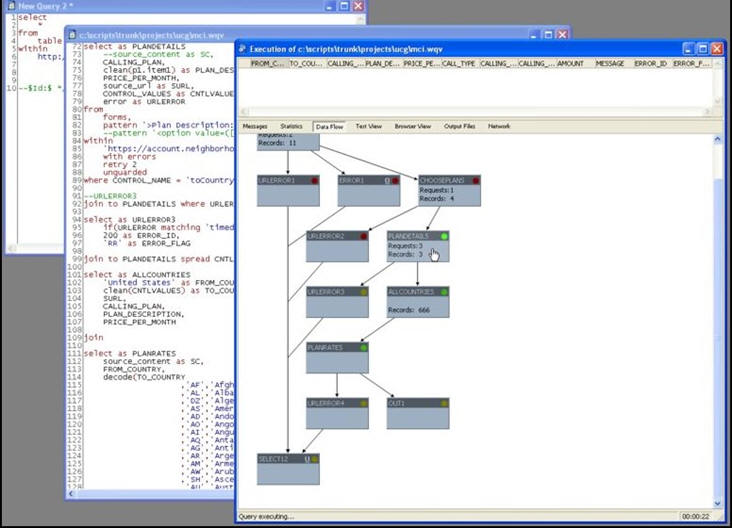
The user interface is not unlike other software that allows you to create code. In the example below, you can see the code in the background and a block diagram of the query that has been constructed. This example includes a geographic search of countries. In the lower left you can see the country codes.
 |
 |
 |
 |
Creating an agent can take anywhere from ten minutes to several hours, depending on the complexity of the search. The agents run in real-time and can be tuned on the fly as data are retrieved and problems are encountered. For example, the agent may report, “I have found a couple of tables; do you want all the data or just some of it?” WebQL reads most database formats natively and can extract data from them even on the Web. The search process can be fairly fast and lots of data can be retrieved quickly. For example, think about how quickly Orbitz or CheapTickets can find fare information from several airlines in response to you launching an agent.
From Our Homepage
Saying Farewell to an Amazing Journey
Communicating with Maps
Is There a GIS Career Ladder?
What does it mean to be geospatially smart? Series
Ways Real Estate and Property Developers Utilize Melissa GeoData for Data-Driven Decisions
Unlocking Value From Daily Satellite Imagery and Insights
Maximizing the Value of Your Address Data with Geo Addressing
How Indoor Mapping Enhances the Security of Smart Buildings
Look Ahead: AI, Location Intelligence and Efficiency
Collaboration Takes on Sea Level Rise & Dynamic Technology Environments
Brownies for Brownfields
Has Everything Been Mapped Already?
How Is Data Literacy Changing in an Artificial Intelligence Landscape
Portfolios for GIS Professionals: More Than Just Maps
How to Create a Distance Matrix in QGIS - A Step-by-Step Guide
7 Ideas for Bringing GIS into the K-12 Classroom
The Geography of Movement