There is no doubt that infrastructure in its
many
forms; roads, bridges, drinking water distribution, electric
distribution; is the lifeblood of modern civilization. It is difficult
to imagine life without them and disruptions are felt widely when they
occur.
Managing infrastructure has unique challenges because of the long life cycle of these assets. It is not uncommon for the lifespan of an infrastructure asset, from commission to decommission, to be 50 to 75 years. There are also some glorious extremes such as the Roman Coliseum, which has been around for two thousand years and is still being used.
The constant work and re-work of these assets over long life cycles has proven difficult to track. At any given time the Owner-Operators do not have immediate access to some of the most fundamental knowledge about the asset, such as location, construction materials and operational state.
Increased pressure, both from the load on the asset and the decreasing budgets to maintain it, have made the gap between what is known and what is reality increasingly important. It is very difficult to plan when you don’t know the current state of a system with some degree of confidence.
Information Management – More than an Engineering Task
Internal and external threats to infrastructure have also unfortunately become a way of life in the 21st century. In addition, natural disasters require the same quick analysis and response to the emergency situation.
Given the newfound ability to locate, manage and access information throughout the various stages of the engineering lifecycle, governments tasked with public safety have begun using the same technology to aid in emergency preparedness.
The ability to locate threatened assets, manage any potential damage to them, and propose quick remediation steps is now made possible using the exact same computerized capabilities used day to day in the previously discussed engineering lifecycle.
Infrastructure damage, whether natural or manmade, must be quickly reviewed and the effects of the damage must be minimized to ensure public safety.
As access to this critical technology expands, government agencies and citizens alike will be able to better respond to homeland security threats as well as other emergencies that threaten public safety.
State of Affairs
Although reality can be much more complex, the lifecycle of an asset can generally be broken down into four phases (as shown below). The asset is designed and documentation is produced to transmit the design intent. The documentation is used to build the asset. Once built, the asset is commissioned and operated. Invariably there is need for expansion and maintenance which triggers a planning phase and then the cycle starts over again.
Before the mass adoption of computers in this field, about 15 years ago, infrastructure lifecycle management was essentially paper based. Engineering drawings would be produced and used by the construction crews to build the asset. All operations and planning were based on these drawings which would be the documents of record for the asset. If you wanted to know where a man-hole was and what materials were used, you would go to the drawing. Of course it was difficult to generate any kind of report (How many man-holes are in existence?) from these documents, as it would be necessary to scan all of them to get an overall view. This paradigm was also error prone and, due to the lack of confidence in the documentation, expensive surveys of the infrastructure asset had to be conducted before any major project commenced.
The mass adoption of computers created a difference in how things got done, although the four phases of infrastructure lifecycle are still followed.
In the design and construction phases, engineering designs are now produced with sophisticated design and modeling software and construction proceeds based on the unprecedented detail that can be generated and included in the documentation. In the operation and plan phases, a new paradigm was ushered in by the mass adoption of databases that first allowed the development of Automated Mapping/Facilities Management (AM/FM) software, and then the development of GIS.
In this paradigm the engineering documentation is transformed, converted and abstracted to fit into the confines of a database, and the GIS is built on it. Once in a GIS, the Owner-Operator can integrate business data into the system and generate sophisticated reports that can be used for operations and planning. It solves the fundamental reporting problem of the paper based paradigm, but it is not without problems.
Transforming, converting and abstracting the engineering data into the GIS proved to be much more difficult than anticipated in an environment that demanded that infrastructure be constantly worked and re-worked. In the last five to seven years the success rate has improved and organizations are successfully managing their assets with these systems. Nonetheless, the “conversion” step remains expensive, not affordable to everyone, fraught with error and most importantly, unsustainable. An alternative to integrating all information into one environment, is organizing the available information in a distributed environment based on multiple representations (the index information and the source information).
A New Way Forward
To this day, the richest and most complete description of an asset still lives in the engineering documentation that was used to build it – the source information. At this point in history the documentation exists in sophisticated digital models, digital drawings, and still, to a large extent in local governments and smaller organizations, in paper drawings. The drawback is that this information is fragmented and distributed over many organizational barriers. In the case of urgent situations such as in the context of homeland security or a major natural disaster such as Hurricane Katrina, there is no time available to discover all relevant information sources from all relevant organizations. It is the responsibility of the government to organize availability and accessibility in an effective manner. This will then enable the reuse of the available information (‘create once, use many times’).
Given that the asset’s richest data is in the engineering drawings, the question becomes – ‘Why convert at all?’ Could the engineering data not be kept in its original form and use the power of the database to index the information in the engineering drawings to create sophisticated reports, thus helping Owner-Operators with the “operate and plan” phases of the infrastructure lifecycle. The result would be a seamless, sustainable, bottom up process to keep information current and reliable. However, instead of isolated documents, the whole could now be considered as an organized system based on multiple representations (source information and abstracted information for index) in a distributed, networked environment. Interesting examples of this approach follow.
Ed. note: This article is part of a series on this topic. Other articles in the series can be accessed below.
A Proposed System Architecture for Emergency Response in Urban Areas By Dr. Sisi Zlatanova
Recycling Geospatial Information in Emergency Situations: OGC Standards Play an Important Role, but More Work is Needed By Marian de Vries
Interoperable Integration of 3D Models over the Internet for Emergency Preparedness and Response By Dr. Thomas H. Kolbe
3D GIS in Support of Disaster Management in Urban Areas By Dr. Jiyeong Lee
Managing infrastructure has unique challenges because of the long life cycle of these assets. It is not uncommon for the lifespan of an infrastructure asset, from commission to decommission, to be 50 to 75 years. There are also some glorious extremes such as the Roman Coliseum, which has been around for two thousand years and is still being used.
The constant work and re-work of these assets over long life cycles has proven difficult to track. At any given time the Owner-Operators do not have immediate access to some of the most fundamental knowledge about the asset, such as location, construction materials and operational state.
Increased pressure, both from the load on the asset and the decreasing budgets to maintain it, have made the gap between what is known and what is reality increasingly important. It is very difficult to plan when you don’t know the current state of a system with some degree of confidence.
Information Management – More than an Engineering Task
Internal and external threats to infrastructure have also unfortunately become a way of life in the 21st century. In addition, natural disasters require the same quick analysis and response to the emergency situation.
Given the newfound ability to locate, manage and access information throughout the various stages of the engineering lifecycle, governments tasked with public safety have begun using the same technology to aid in emergency preparedness.
The ability to locate threatened assets, manage any potential damage to them, and propose quick remediation steps is now made possible using the exact same computerized capabilities used day to day in the previously discussed engineering lifecycle.
Infrastructure damage, whether natural or manmade, must be quickly reviewed and the effects of the damage must be minimized to ensure public safety.
As access to this critical technology expands, government agencies and citizens alike will be able to better respond to homeland security threats as well as other emergencies that threaten public safety.
State of Affairs
Although reality can be much more complex, the lifecycle of an asset can generally be broken down into four phases (as shown below). The asset is designed and documentation is produced to transmit the design intent. The documentation is used to build the asset. Once built, the asset is commissioned and operated. Invariably there is need for expansion and maintenance which triggers a planning phase and then the cycle starts over again.
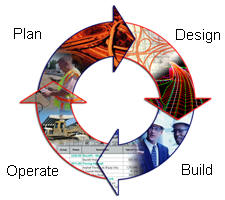 |
Before the mass adoption of computers in this field, about 15 years ago, infrastructure lifecycle management was essentially paper based. Engineering drawings would be produced and used by the construction crews to build the asset. All operations and planning were based on these drawings which would be the documents of record for the asset. If you wanted to know where a man-hole was and what materials were used, you would go to the drawing. Of course it was difficult to generate any kind of report (How many man-holes are in existence?) from these documents, as it would be necessary to scan all of them to get an overall view. This paradigm was also error prone and, due to the lack of confidence in the documentation, expensive surveys of the infrastructure asset had to be conducted before any major project commenced.
The mass adoption of computers created a difference in how things got done, although the four phases of infrastructure lifecycle are still followed.
In the design and construction phases, engineering designs are now produced with sophisticated design and modeling software and construction proceeds based on the unprecedented detail that can be generated and included in the documentation. In the operation and plan phases, a new paradigm was ushered in by the mass adoption of databases that first allowed the development of Automated Mapping/Facilities Management (AM/FM) software, and then the development of GIS.
In this paradigm the engineering documentation is transformed, converted and abstracted to fit into the confines of a database, and the GIS is built on it. Once in a GIS, the Owner-Operator can integrate business data into the system and generate sophisticated reports that can be used for operations and planning. It solves the fundamental reporting problem of the paper based paradigm, but it is not without problems.
Transforming, converting and abstracting the engineering data into the GIS proved to be much more difficult than anticipated in an environment that demanded that infrastructure be constantly worked and re-worked. In the last five to seven years the success rate has improved and organizations are successfully managing their assets with these systems. Nonetheless, the “conversion” step remains expensive, not affordable to everyone, fraught with error and most importantly, unsustainable. An alternative to integrating all information into one environment, is organizing the available information in a distributed environment based on multiple representations (the index information and the source information).
A New Way Forward
To this day, the richest and most complete description of an asset still lives in the engineering documentation that was used to build it – the source information. At this point in history the documentation exists in sophisticated digital models, digital drawings, and still, to a large extent in local governments and smaller organizations, in paper drawings. The drawback is that this information is fragmented and distributed over many organizational barriers. In the case of urgent situations such as in the context of homeland security or a major natural disaster such as Hurricane Katrina, there is no time available to discover all relevant information sources from all relevant organizations. It is the responsibility of the government to organize availability and accessibility in an effective manner. This will then enable the reuse of the available information (‘create once, use many times’).
Given that the asset’s richest data is in the engineering drawings, the question becomes – ‘Why convert at all?’ Could the engineering data not be kept in its original form and use the power of the database to index the information in the engineering drawings to create sophisticated reports, thus helping Owner-Operators with the “operate and plan” phases of the infrastructure lifecycle. The result would be a seamless, sustainable, bottom up process to keep information current and reliable. However, instead of isolated documents, the whole could now be considered as an organized system based on multiple representations (source information and abstracted information for index) in a distributed, networked environment. Interesting examples of this approach follow.
- KLIC (cable and pipeline information center) in the Netherlands (and probably also in several other countries) – the actual information is stored at the utility operating organization, but is accessible via a central index.
- Cadastral map (in many countries of the world) – the real information is reflected in the survey plans and the legal documents; the cadastral map itself is considered in many countries as just an index to organize the involved source documents.
- One important question is, 'What geometric and thematic information from the source documents should be indexed?’ Of course, location itself is important, but how detailed should this be? Considering the fact that we are dealing with infrastructure such as pipelines, a single point location may not be a good entry in the index; at least a polyline is needed. Does it need to be 3D?
- Another question: 'Which thematic information is relevant for searching via the index?' Many aspects are relevant: date of design/construction, type of material involved, date of last maintenance, name of designer, etc. This could be called metadata, but remember, one person's metadata may be the other person's data. Besides design documents (drawings), other types of source documents may be relevant in the context of homeland security: detailed surveys (as design may differ from creation in reality or changes may have occurred after initial construction), high resolution satellite (or aerial photography) images, etc. These types of information should also be accessible as they may give an indication regarding the current status.
- Once the previous two questions have been answered, the next question is: 'How to obtain this information?' Clearly, doing everything manually will require a huge effort and a lot of time. Automating this process may give significant benefits. However, the challenges are also significant, because in order to understand the information in the different source documents (and harmonized index) some (formal) semantics are needed. Also, if the 'requirements' of the indexing are known, then the future source documents may be extended (compare extending html documents with invisible tags for search engines, such as Google).
- Assuming the initial index has been created and filled with relevant search information, the final research question is 'How can the information in the index be maintained as the source documents change?' Basically, this is a generic distributed information management question. Especially in an emergency situation, it may be unacceptable to track links to source documents that are invalid.
Ed. note: This article is part of a series on this topic. Other articles in the series can be accessed below.
A Proposed System Architecture for Emergency Response in Urban Areas By Dr. Sisi Zlatanova
Recycling Geospatial Information in Emergency Situations: OGC Standards Play an Important Role, but More Work is Needed By Marian de Vries
Interoperable Integration of 3D Models over the Internet for Emergency Preparedness and Response By Dr. Thomas H. Kolbe
3D GIS in Support of Disaster Management in Urban Areas By Dr. Jiyeong Lee
From Our Homepage
Saying Farewell to an Amazing Journey
Communicating with Maps
Is There a GIS Career Ladder?
What does it mean to be geospatially smart? Series
Ways Real Estate and Property Developers Utilize Melissa GeoData for Data-Driven Decisions
Unlocking Value From Daily Satellite Imagery and Insights
Maximizing the Value of Your Address Data with Geo Addressing
How Indoor Mapping Enhances the Security of Smart Buildings
Look Ahead: AI, Location Intelligence and Efficiency
Collaboration Takes on Sea Level Rise & Dynamic Technology Environments
Brownies for Brownfields
Has Everything Been Mapped Already?
How Is Data Literacy Changing in an Artificial Intelligence Landscape
Portfolios for GIS Professionals: More Than Just Maps
How to Create a Distance Matrix in QGIS - A Step-by-Step Guide
7 Ideas for Bringing GIS into the K-12 Classroom
The Geography of Movement