Back to Part One.
On to Part Three.
Evidently we need to find a better solution. Several design choices present themselves:
- Do we continue to represent the farms as point data with emissions values or do we represent the farm emissions as values within a grid, as suggested above?
- Do we have to represent the kernel as a grid of cells or is there perhaps a better way?
Unfortunately, the purpose our modeler has in mind is more demanding. He wants to evaluate different scenarios. What happens if emissions can be reduced at one set of farms? Where should they be reduced, and by how much, to get total deposition below a threshold? This requires making frequent modifications to the data and running the model again and again. In such circumstances people need computation to be immediate.
If we take “immediate” to mean within one minute, which is typical of even simple operations on large grids, then we have a long way to go.
What can be done to speed up the convolution?
The obvious thing is to keep the representation of the farms as 4,000 points, rather than converting them into an emissions grid. After all, the grid has three million cells, which are 750 times as many as we really need. This suggests two solutions.
The first is output-oriented. To compute the value of each cell in the output grid, we find each farm within 3000 meters of the cell and add its contribution (as computed from the kernel function) to the output cell. This solution suffers from the need for a farm-finding algorithm, which could slow down the process significantly.
The second is input-oriented. The kernel really is just a method that directly spreads one value (a farm’s annual emissions) from a point (the farm) into its neighborhood. If this spreading operation is fast enough, we might be able to do it 4,000 times over in a short period of time. It is superior to the first in not requiring any searches for nearby farms.
The second approach can be done with Spatial Analyst, using its “gridIO” library functions and some Avenue scripting. (Kenneth McVay, a prolific and generous programmer, has provided an Avenue interface to gridIO for the intrepid or desperate analyst. See his “CellIO” script). The calculation shrinks to eight hours using this approach. On a faster workstation, it could be done in less than three hours. We will revisit this “direct” method, but first let’s cast about for a different solution.
How about a non-gridded representation of the kernel? Although attractive, it is not clear it could lead to a superior method. Any method to represent the kernel ultimately must lead to computations on the kernel grid. (Remember those arrows in the figure: the value for each arrow must be computed somehow.) We are probably better off doing those computations once and for all, recording them on a kernel grid, and letting the computer look up the values in that grid. Lookups are almost always faster than computations, when you have the RAM for it.
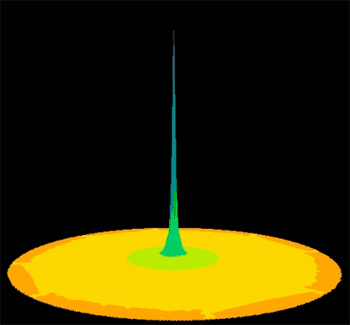
By the way, here is a hillshaded representation of our modeler’s deposition kernel. It has a sharp peak in the center and tapers almost exponentially away. It is cut off at a 3,000 meter radius.

The deposition kernel (hillshaded relief). Blue = high, red = low. It takes discontinuous steps at 100 and 1000 meters; the radius is 3000 meters. See it spatial perspective.
{kind=link}
| 3. Can we be clever? |
The problem asks specifically for a Spatial Analyst solution. The first thing is to review the Spatial Analyst toolkit. The documentation refers to the things you can do with grids as “requests”. They are all listed on one help page (under the “Grid(class)” topic). Quite a few requests look suspiciously like convolution. The most promising ones include:
- Filter - Performs a “focal filter” on a grid.
- FocalStats - Calculates a statistic (such as an average) for a user-defined neighborhood, for each cell. Each cell has a unique overlapping neighborhood.
- MakeByInterpolation - Includes the IDW method, which can be considered the result of two intermediate convolutions.
- MakeDensitySurface - Converts a point theme to a grid and then convolves with a constant circular kernel or an approximate Gaussian kernel.
Most of these requests have obvious built-in limitations. “Filter,” for example, is a convolution with a specific 3 x 3 grid. Two such convolutions are equivalent to a convolution with a 5 x 5 grid, three convolutions with a 7 x 7 grid, and so on. (Each successive convolution spreads the grid values two cells further away.) However, it would take 60 such operations to spread out to 120 cells away, and we don’t get any choice of kernel. That looks like a dead end.
The MakeDensitySurface request could be used in some circumstances, but the two kernels it uses are very flat in the vicinity of the input cell. They just cannot be readily combined to reproduce the sharp peak of our kernel.
What about the IDW technique? I mentioned earlier that it is really two convolutions. Its kernel tapers off according to some inverse power of distance. The power is under user control. Any inverse power of distance is sharply peaked (infinite, actually) near the input cell, which is good for us. Unfortunately, the IDW output from Spatial Analyst does not allow one to recover the intermediate convolutions that were performed. There seems to be no way around this.
That leaves us with the most obvious candidate, FocalStats, which we already know to be too slow.
| 4. Hitting the literature |
One of the greatest benefits of recognizing what it is we are doing is that it connects us with centuries of scholarship and clever thinking. By knowing at least the name for this operation—convolution—we have a key to this literature. A little research will reveal a wonderful related technique: Fourier transforms.
The Fourier transform was developed two centuries ago as a tool for writing (nearly) arbitrary functions as sums of trigonometric series. However, we do not really need to know much about it. The key points are:
- The Fourier transform produces a new grid of the same size and shape as the original grid.
- Computing the Fourier transform takes a number of computer operations that is roughly proportional to the number of cells in a grid. (This is the “Fast Fourier Transform,” or FFT.)
- With minor modifications, the Fourier transform is its own inverse: applying it twice produces a grid that is related to the original grid in a very simple manner.
- To do the FFT really quickly requires holding the entire grid in RAM at once.
- You actually need to put a special “collar” of zero values around your grid to do the FFT correctly, so it takes more RAM than you think.
- Take the FFT of the emissions grid.
- Take the FFT of the kernel grid.
- Multiply the two FFTs.
- Take the inverse FFT of that product.
The origin of this project.
On to Part Three.
Back to Part One.